OpenStreetMap est une bonne alternative pour le fond de carte et de nombreux services existent aussi pour les calcul d’itinéraire (osrm, mais aussi graphoper). Là où ça pêche le plus c’est sur le géocodage.
Nominatim, le service maintenu par la fondation OSM n’est malheureusement pas au niveau de service actuellement attendu. Il ne tolère aucune erreur de saisie, n’est pas assez rapide pour gérer de l’autocomplétion. Par contre, il indexe très bien les données OSM en les hiérarchisant et en ne se limitant pas uniquement aux adresses.
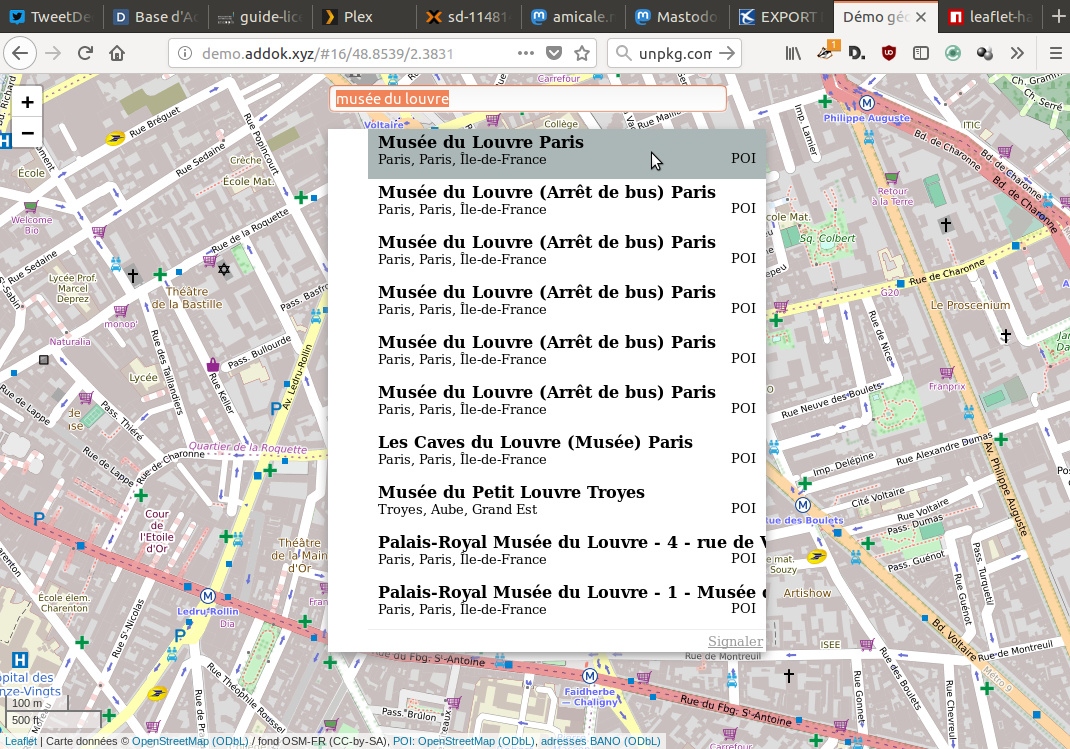
Je suis donc en train d’avancer sur le géocodage… en allant plus loin qu’un référentiel contenant uniquement les adresses.
J’avais déjà testé addok (le géocodeur de adresse.data.gouv.fr) avec des POI issus d’OSM, des entreprises issues de SIRENE, donc là j’essaye de mixer le tout pour avoir un service assez universel qui puisse se substituer aux services « place » de GMaps.
Complément: voici la liste des endpoints addok que je fais tourner à titre de démo/test:
- ban.addok.xyz (identique en principe à api-adresse.data.gouv.fr)
- bano.addok.xyz avec les données BANO
- poi.addok.xyz avec les POI d’OSM
- demo.addok.xyz (BANO + POI combinés), visible sur https://demo.addok.xyz