Bonjour Christian ! J’ai commencé à travailler sur les données mises à disposition par Code For France. Mais peut-on vraiment en faire quelque chose ? Comme il n’y a pas de possibilité de voter/commenter une proposition (comme c’est le cas sur les autres plateformes mises en place par Cap Collectif), on se retrouve avec une énooooooorme liste de doléances, sans possibilité de tri.
Ou alors il existe des outils d’analyse de langage que je ne connais pas et qui permettraient de tirer du sens de tout ça ? Je m’interroge.
Je ne suis pas totalement débutant en la matière, mais je suis preneur de conseils, de méthodes d’analyse et d’outils pour le faire. Pour le moment, je cherche à détecter les entités nommées et leur présence dans une des réponses du questionnaire, via l’API de TextRazor.
Il existe effectivement plusieurs bibliothèques python qui permettent de faire des choses sympas (clustering de texte, analyse sémantique latente, détection d’entités nommées etc). Les plus utilisées actuellement sont gensim et spaCy. Cette dernière dispose également un wrapper R.
Pour une approche plus intégrée, je conseillerais de regarder du côté des outils développés par les consortiums de journalistes comme aleph de l’OCCRP ou le tout frais datashare de l’ICIJ, qui font notamment de l’indexation de documents par entités nommées.
(Aleph utilise spaCy, datashare utilise une autre bibliothèque très utilisée Stanford CoreNLP qui dispose depuis peu d’un package python amélioré StanfordNLP.)
Absolument.
gensim peut charger des plongements lexicaux fasttext ou word2vec, qui sont disponibles pour de nombreuses langues dont le français et téléchargeables par ailleurs.
spaCy fournit des modèles pour le français: https://spacy.io/models/fr , Stanford CoreNLP et StanfordNLP aussi.
Deux points risquent de gêner un peu l’analyse.
Premièrement, l’utilisation de langue non standard (variantes de graphies, fautes de frappe, typographie non standard…) introduit pas mal de variabilité ; normalement la solution la plus robuste à ces variations pour faire du clustering est d’utiliser les vecteurs fasttext dans gensim.
Deuxièmement, les modèles qui font de la reconnaissance d’entités nommées sont également assez sensibles à ces variations de graphie et aux différences de domaine (en gros, les termes et entités spécifiques à un contexte) entre les corpus sur lesquels les modèles ont été entraînés, et les données auxquelles vous voudrez les appliquer. Donc la reconnaissance d’entités nommées devrait récupérer pas mal de mentions d’entités, mais avec un taux d’erreurs ou d’oublis qui restera assez important. Idéalement, il faudrait ré-apprendre des modèles sur les données du grand débat ou adapter un modèle existant à ces données
Bonjour, chez semdee.com c’est notre mission d’aider à analyser d’immenses corpus de données textuelles. Nous analysons actuellement les contributions.
Notre solution ne rencontre pas ce genre de difficultés, nous prenons en compte le contexte global, bien plus que les mots.
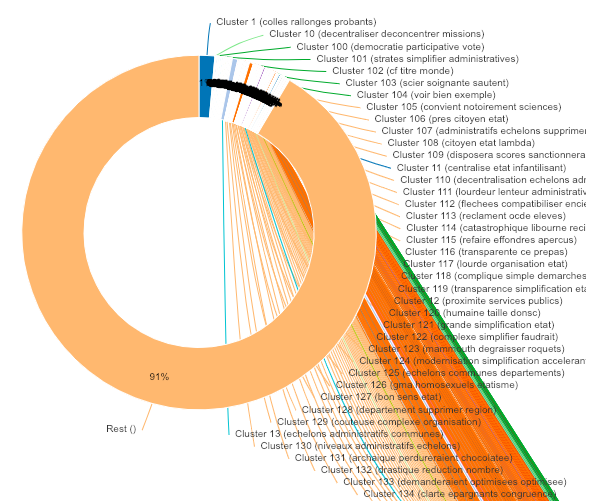
Exemple : clustering non supervisé de 28000 contributions mettant en évidence les doublons ou les contributions modifiées par un même contributeur
Bonjour @SebSemdee, merci de partager vos résultats avec la communauté #TeamOpenData.
Si je lis bien votre graphique, 91% des contributions n’appartiennent à aucun cluster. Comment pensez-vous gérer ce problème de dispersion?
Effectivement, le cluster 1 semble regrouper des contributions identiques issues de copier/coller d’un message préparé et diffusé par un ou des tiers comme la “Ligue de Défense des Conducteurs”: https://forums.automobile-propre.com/topic/dire-stop-au-80-kmh-sur-route-sur-le-granddebatfr-13520/ . Les termes clés ici étant “collés” (“camions collés aux voitures”), “rallongés” (“temps de trajet rallongés”) et “probants” (“avec des résultats peu probants”).
Les autres clusters produits regroupent-ils également tous des contributions “concertées”, ce qui voudrait dire que les 91% de contributions hors clusters sont des contributions uniques?
Ce site permet de tagguer collaborativement par crowdsourcing les contributions publiques déposées sur granddebat.fr
Le principe est simple: une réponse (ouverte) à une question vous est présentée avec les “tags” correspondant aux idées principales.
A vous de sélectionner les tags correspondant et de valider (ou passer si impossible à traiter).
La démarche est complètement ouverte
Le code (php) est sur github (si vous avez des issues ou PR à proposer) et les données de tagging disponibles en CC-BY-SA.
Ceci permettra peut être d’envisager de l’analyse supervisée (ou de simples statistiques), car ceux qui ont tenté le non supervisé n’ont pas eu de résultats bien probants pour l’instant (les 91% ci-dessus).
N’hésitez pas à faire circuler pour passer du teamsourcing au crowdsourcing
C’est une question de méthode. Pour le moment je me suis attaché à identifier les contributions très proches, mettant en évidence les doublons.
Je vais cleaner les doublons qui introduisent un biais. Ensuite je vais lancer un clustering différent pour voir les différentes tendances
Bonjour @cquest,
Excellente idée, cette plateforme d’annotation collaborative pour ces contributions !
Par contre je n’ai pas trouvé le nom de la structure ou de la personne responsable de la plateforme (dans les mentions légales), à moins que j’aie manqué quelque chose?
Merci !
L’indexation des 28.000 contributions prend quelques secondes, sans aucune ontologie à préparer ni aucun modèle à entrainer.
Le clustering se fait en quelques secondes, il permet de faire des découvertes sans a priori, 2 réglages simples, la distance entre les documents et le nombre de documents pour former un cluster.
Ensuite selon les tendances je crée des catégories, pour organiser les contributions à partir de patterns, la plate-forme distribue les contributions dans les catégories selon leur proximité avec les patterns