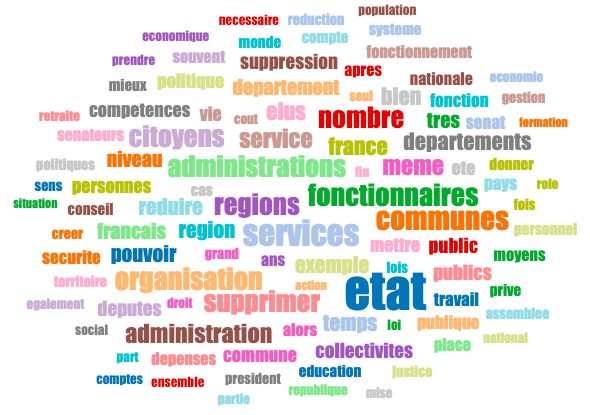
Ici les 100 premiers tags les plus discriminants, il ne s’agit pas d’un comptage de mots, on observe la distance de leur contribution d’appartenance avec le sens moyen de la somme de toutes les contributions, comme si un humain avait lu toutes ces contributions et en avait retenu les principales informations. A ce stade de mes découvertes, à la question sur l’organisation de l’Etat et des services publics, les deux grandes tendances semblent être une lourdeur administrative qu’il faudrait alléger pour être beaucoup plus proches des citoyens, et supprimer les échelons administratifs perçus comme le moyen de rémunérer des personnes haut placées éloignées des réalités de la vie. Je vais regarder les autres questions pour mettre en évidence d’autres tendances
La plateforme d’annotation est liée à un dépôt git sur github : https://github.com/fm89/granddebat, créé par l’utilisateur fm89, ça renseigne pas sur tout mais ça donne une piste pour contacter le créateur du service et voir si ca démarche est pérenne dans le temps https://github.com/fm89
Bonjour ! Pour des collègues journalistes, je commence aussi à regarder afin d’essayer de mesurer le poids de certains termes dans les contributions (“retraites”, au hasard). Mais je dispose de peu de temps et crains de ne pas parvenir à assimiler les outils d’analyse sémantique déjà cités !
Pierre Magistry a produit des graphes sémantiques sur des données proches mais d’une autre plateforme (noos-citoyens): https://noos-citoyens.fr/isc-explorer
Si l’une ou l’autre vous semble pertinente, vous pouvez contacter leurs auteurs.
@mathieu@Guihero Bonjour et merci beaucoup pour votre intérêt pour cette initiative.
Le serveur restera en ligne aussi longtemps que nécessaire pour l’analyse collaborative des données (peut-être sur un serveur moins puissant une fois le pic passé). Les données sont publiées chaque nuit et seront de toute façon déposées dans une archive ouverte à l’issue du processus.
Nous sommes une petite équipe de particuliers. Nous n’avons pas d’association (d’où l’absence de nom dans les mentions légales). Nous sommes néanmoins ouverts à un portage du projet par une ou plusieurs associations spécialisées, notamment pour améliorer la plateforme et atteindre le volume critique nécessaire de participants.
Nous serions heureux de vous rencontrer pour discuter du futur de la plateforme et d’un passage à l’échelle ! Vous pouvez effectivement nous contacter à notre adresse gmail granddebat.ovh.
Le grand débat c’est une plate-forme mais aussi des cahiers dans les mairies.
Suite à des propos peu claires du gouvernement voici une série d’articles sur l’avenir de ces cahiers et notamment leur numérisation mises en données :
Pour les cahiers, il me semble que c’est la BnF qui a été chargée de les numériser et de les archiver.
Ce qui pose plus problème, c’est l’exploitation (dans des délais courts) de leur contenu car il est “au kilomètre”.
Des appels d’offres ont aussi été lancés par le gouvernement pour la numérisation et l’analyse. Pour la volumétrie, on y parle de plusieurs centaines de milliers de pages.
Oui ce point est traité dans les articles que j’ai posté.
Effectivement, j’attends de voir les délais de traitement puisqu’il est question d’OCR sur de l’écriture manuscrite + de la transcription. Il faudrait voir les appels d’offres (donc monté et attribué en un temps records).
en tant qu’archiviste un grand questionnement sur le fait que le gouvernement semble à ce point méconnaître notre métiers, nos fonctions et mêmes nos compétences.
Je me demandais s’il y avait eu des tentative sur la classification de documents sur la base de l’annotation faite sur https://github.com/fm89/granddebat
Je fait du machine learning / deep learning dans mon métier mais j’ai peu de pratique sur des données
texte malgré quelques lectures dans le domaine (je fais plus de l’image ou des données tabulaire).
Je pensais utilisés des méthodes pré-entrainé type ULMFiT ou BERT pour les connaisseurs.
Avec un bon pré-processing, il y a surement moyen d’éviter les problèmes du dataset (mauvaise orthographe …).
@mathieu : Tu sembles être la personne qui connait le mieux ls technique de NLP. Qu’en penses tu ? Penses-tu que c’est faisable ? As-tu des approches à conseiller pour cette tache ?
Bonjour @Olivier_n,
Je ne sais pas si des tentatives de classif ont déjà eu lieu, peut-être que @fm89 est au courant d’initiatives en ce sens?
Je partirais aussi sur ULMFiT et BERT, ainsi que fasttext et ELMO.
En première approche, je commencerais par faire des expés avec les modèles déjà dispos pour le français ou multi-lingues:
Il faut effectivement être attentif au pré-processing (normalisation, filtrage…) qui a été appliqué pour chaque ressource (modèle ou vecteurs) car le code source n’est pas toujours cohérent avec le papier, soit d’emblée soit que ça a changé dans des versions successives.
Pour raccourcir les expés, tu peux essayer dans un 1er temps de découper chaque contribution en phrases au préalable, avec StanfordNLP (c’est le tokenizer processor qui fait ça, pas besoin de charger le modèle complet) ou spaCy, et d’appliquer ELMO/BERT/… séparément sur chaque phrase.
Il est possible que la perte en qualité de prédiction soit négligeable pour un gain en rapidité énorme, ce qui est d’autant plus intéressant pour itérer rapidement dans des expés préliminaires.
Je laisse les autres contributeurs compléter avec leurs idées !
Bonjour,
Nouvellement inscrit, je vous propose néanmoins une petite appli supplémentaire qui permet de se représenter les événements programmés au travers de quelques graphiques simples et visualisations https://jgorene.github.io/grand-debat-rdv/
Les analyses réalisées sont très simples mais peuvent s’avérer utiles selon le besoin et l’usage.
L’outil n’est qu’un simple prototype expérimental… en tout cas sans comparaison avec les outils professionnels que j’ai déjà pu voir dans cette discussion
Un des avantages éventuel de cette outil : la possibilité d’utiliser directement un fichier csv avec l’interaction possible à partir d’un mot-clé.
Une des limites : le fichier doit avoir la même structure que celui fourni sur le site du grand débat pour les événements (important).
Sinon, tout est ouvert et le code est disponible sur mon compte github en lien.
Vos retours sont bienvenus le cas échéant, merci…
A priori, je n’ai pas connaissance de classification automatisée qui soit sortie pour le moment (que ce soit à partir des données brutes en non supervisé ou à partir du jeu annoté en supervisé).