J’ai en effet reçu un mail de l’INPI il y a quelques jours :
Vous voudrez bien trouver en pièce jointe la nouvelle version de la documentation technique sur les IMR consolidées. La mise à jour concerne les informations des bénéficiaires effectifs.
Ces données semblent donc désormais mises à disposition avec les données sur les Immatriculations, modifications, radiations (IMR) qui sont accessibles via FTP après une demande d’accès. @cquest pourra peut-être confirmer et dire si c’est déjà archivé sur son serveur. J’en profite pour mentionner aussi @Leolecolo que ça intéressera également.
C’est moi qui cherche mal ou ce n’est pas ouvert ?
En revanche si tu fais référence au fait que l’INPI ne respecte pas la loi puisque les données ne sont pas véritablement ouvertes, on est bien d’accord… On s’en plaignait déjà en 2019. Espérons qu’elles soient un jour toutes sur annuaire-entreprises.data.gouv.fr !
Ces informations sur les bénéficiaires sont accessibles, pour le grand public, sur le portail DATA INPI et, pour les professionnels de la lutte contre le blanchiment, par le biais de licences gratuites accordées par l’INPI.
J’ai donc l’impression que l’on peut consulter unitairement les informations lorsqu’on recherche une entreprise, mais que l’accès global au jeu de données n’est pas ouvert à tout le monde.
On a bien les informations dans la page HTML, mais j’avoue n’avoir pas regardé si les données téléchargeables avaient eu une évolution. La doc indiquée par Johan indique que c’est désormais présent dans les XML mais ceux-ci ne sont disponibles qu’à travers une API à ce qu’il me semble.
Le problème c’est que mes scripts récupèrent des CSV par FTP, rien d’autre.
Même pour les « autorités de contrôle (l’article R. 561-57 du Code monétaire et financier en dénombre 18) et les personnes assujetties à la lutte contre le blanchiment des capitaux et le financement du terrorisme mentionnées à l’article L. 561-2 du code monétaire et financier », l’accès semble se faire quasi unitairement (fourniture du SIREN ou dénomination de l’entreprise) et pas en téléchargement d’un jeu de données complet, ni même en recherche depuis un bénéficiaire.
Cette transmission est effectuée dans un format informatique ouvert de nature à favoriser l’interopérabilité de ces retraitements et leur réutilisation dans les conditions prévues au titre II du livre III du code des relations entre le public et l’administration et à assurer leur compatibilité avec le registre national dont l’Institut national de la propriété industrielle assure la centralisation en application du 2° de l’article L. 411-1 du code de la propriété intellectuelle.
Les modalités de cette transmission sont définies par décret. https://www.legifrance.gouv.fr/jorf/id/JORFTEXT000041566891
« Seules sont accessibles au public, les informations relatives aux nom, nom d’usage, pseudonyme, prénoms, mois, année de naissance, pays de résidence et nationalité des bénéficiaires effectifs ainsi qu’à la nature et à l’étendue des intérêts effectifs qu’ils détiennent dans la société ou l’entité. »
Donc c’est bien la partie allégée qui est accessible (et communicable) au public, en gros ce qu’on peut voir sur le site web.
« L’accès aux informations relatives aux bénéficiaires effectifs est gratuit, quelles que soient les modalités de consultation ou de communication de ces informations. » C’est mieux en l’écrivant !
Ne reste plus qu’à demander à l’INPI de publier un jeu de données intégral (et pas au goutte à goutte) de ces informations, librement accessible et aisément réutilisable par une machine…
Tu t’occupes de voir avec ouvre boite ? La demande peut être relativement succinte, c’est surtout au tribunal administratif que l’argumentaire joue.
C’est quoi l’article de loi ou le décret qui fait référence là dessus ?
Enfin, la consultation en ligne de documents administratifs librement communicables ne peut être subordonnée à la création préalable d’un compte personnel que dans le cas où la création de ce compte s’effectue de façon est générée automatiquement, sans validation ou intervention l’usager. Quelles sont les modalités de diffusion en ligne ? | CNIL
S’agissant des modalités de publication en ligne, la commission considère que la consultation sur internet de documents librement communicables ne saurait être subordonnée à une procédure de demande d’accès impliquant une autorisation préalable de l’administration. L’administration peut uniquement soumettre l’accès à l’ouverture d’un compte personnel, à condition que la création de ce compte soit générée automatiquement sans intervention de sa part. Une publication dans ces conditions n’équivaut cependant pas à une diffusion publique au sens de l’article L. 311-2 du code des relations entre le public et l’administration (20180003).
L’avis qui fait référence est le suivant :
S’agissant des données en accès restreint, la commission a constaté que le téléchargement des données était de mise en œuvre difficile. Elle ne lui a pas permis en l’état de télécharger les données sollicitées.
La commission considère que, dès lors qu’ainsi qu’il a été dit, les périmètres de protection sollicités constituent des données publiques librement communicables, l’administration ne pouvait soumettre leur téléchargement à une procédure d’accès restreint. En outre, elle estime que les documents sollicités ne peuvent être regardés comme ayant été mis à disposition « dans un standard ouvert, aisément réutilisable et exploitable par un système de traitement automatisé » au sens de l’article L300-4 du code des relations entre le public et l’administration, ni comme ayant fait l’objet d’une diffusion publique au sens du quatrième alinéa de l’article L311-2 du même code.
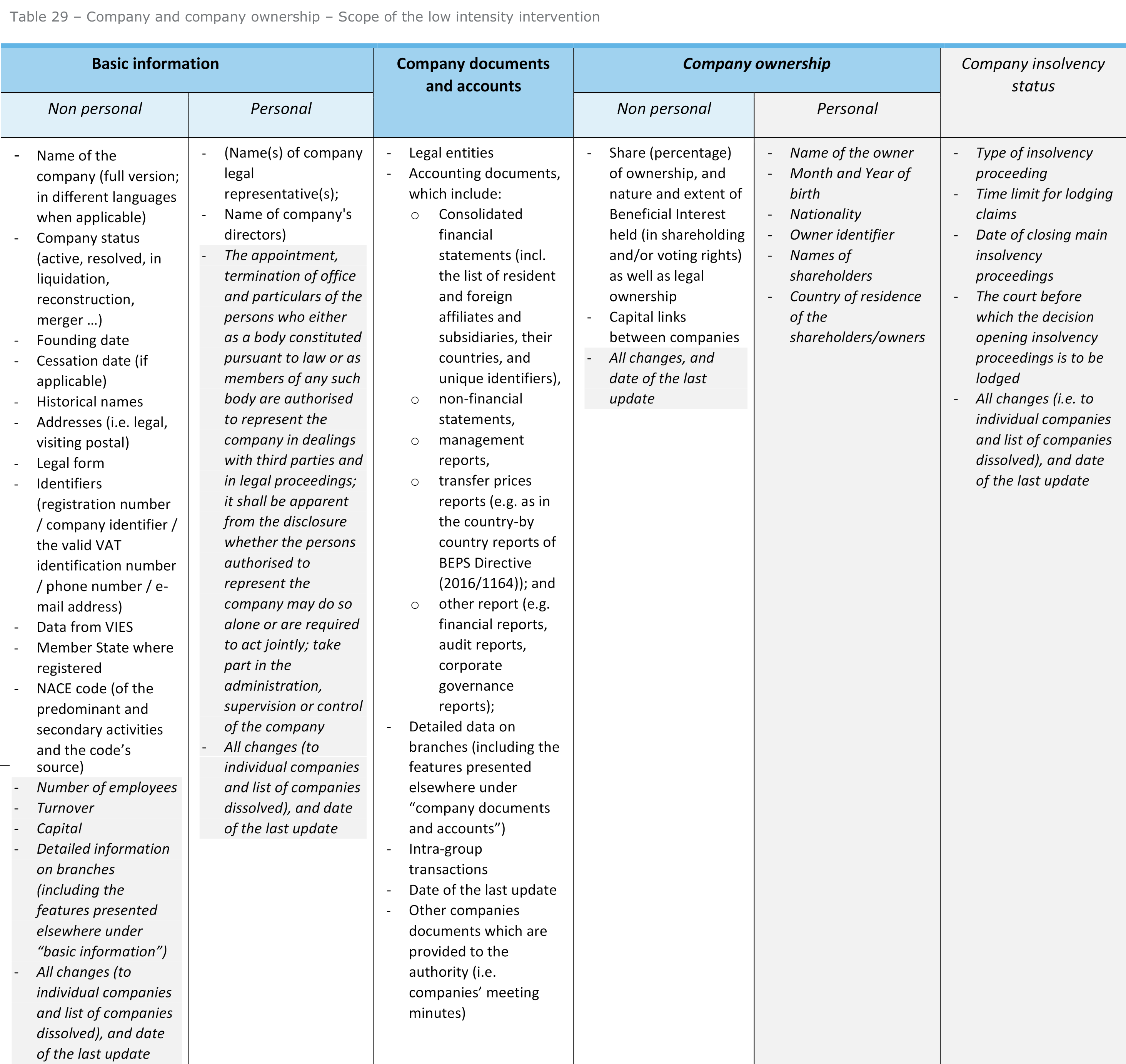
Et Deloitte créa l’open data de « basse intensité ». Belle inventivité de consultant !
Des suggestions potentiellement dangereuses dans cette étude d’impact (à laquelle s’est associée ODI…), même si elles peuvent paraître anodines car ensevelies sous d’autres recommendations globalement en faveur de l’ouverture. Je pars donc du principe que Access Info a de bonnes raisons de sonner l’alarme.
En gros les High Value Datasets seraient dans tous les cas ouverts à 100 %, mais leur assiette pourrait être réduite. C’est cette option au rabais qui est pudiquement appelée « publication de basse intensité ».
Focus sur les données entreprises : en gris l’option considérée comme de « haute intensité ». Les noms des propriétaires (dont les bénéficiaires effectifs) en font partie.
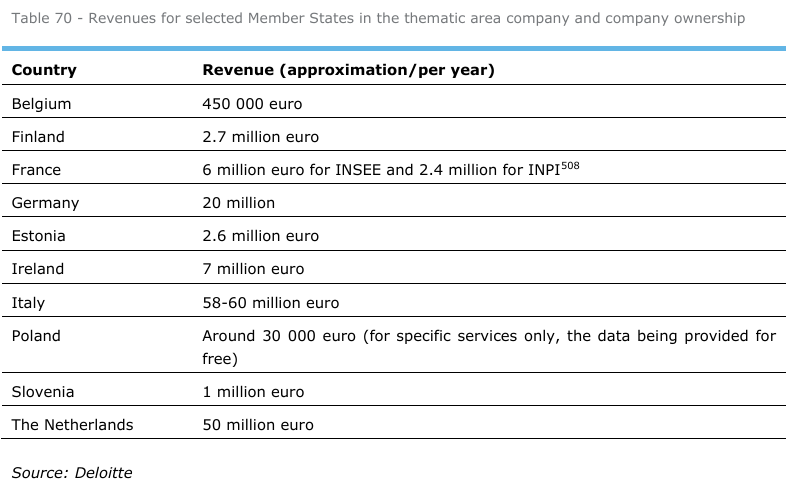
La perte de revenus potentiels est évidemment utilisée pour justifier cette option. Deloitte a ainsi estimé les revenus annuels tirés par les Etats de ces données, qui seraient donc totalement perdus dans le cas de l’option « haute intensité » :
Une note de page apporte cette information pour la France :
Before the transition to an open data model in 2017, a compensation of 11 million euro was attributed to INSEE since but no compensation was foreseen for INPI.
On trouve dans le rapport une autre information :
France: INPI spends around 2-3 million euro per year in developing and maintaining the API infrastructure and underpinning IT system for the trade register.
Ce que l’étude manque de préciser c’est que le cadre légal français impose déjà l’option « haute intensité » et interdit de toute façon la vente de telles données. Donc ces revenus doivent être considérés comme perdus quelles que soient les évolutions au niveau européen liées à ces High Value Datasets.
"Je souhaite la publication en ligne de ces documents dans un format numérique, ouvert et réutilisable (article L. 300-4 du CRPA). "
Vu que c’est accessible librement sur data.inpi.fr ils peuvent très bien répondre que c’est déjà le cas (c’est en HTML, un format ouvert et réutilisable par une machine, qui m’a permis de commencer le scraping).
Ce qu’il fallait demander c’est un export complet, des données accessibles au public prévues par le 2° de l’article L561-46 du code monétaire et financier.
En substance : tout est OK les données sont publiques, et comme il y a des données personnelles c’est normal de mettre des gardes-fous.
Un passage me chiffonne :
De même, comme vous l’avez noté, un compte
utilisateur est requis, le cas échéant, pour un accès en masse aux données
ou pour un accès plus complet à ces informations et actes associés, cet
accès via une simple identification déclarative, sans procédure
d’autorisation préalable, assurant d’une part, un lien vertueux de
communication d’informations techniques avec les réutilisateurs
« professionnels », et permettant d’autre part, la prise de connaissance,
par tous les réutilisateurs, des obligations spécifiques figurant dans
les licences homologuées de réutilisation, étant précisé la particularité
des informations mises à disposition dans le cadre du RNCS, qui
contiennent un grand nombre de données à caractère personnel.
Sauf que les données accessibles en masse sur le FTP, c’est les CSV, et ils ne contiennent pas les données des bénéficiaires effectifs (ou alors j’ai pas compris les en-têtes).