Je n’avais pas noté le type geojson dans le table schema. Découverte très utile. Je pense que je peux rester sur table schema, du coup. Il s’accorde mieux, je pense, à une table géographique de type geopackage.
Je pense qu’un champ autorisé de type WKT aurait été assez intéressant dans table schema, notamment car ce type de champ est assez courant dans le monde de la géomatique. En particulier, un champ WKT peut être lu et exporté depuis un outil comme QGIS. Par contre, je pense que le geojson fait encore figure d’alien dans le monde du SIG. Il y a 20 fois plus de geojson que de shp dans datagouv.
Apparemment, je peux implémenter les sélections multiples en table schema via array
Si j’implémente le type geojson et le type array dans un schéma, ce dernier sera-t-il interprété et lu correctement sur schema.data.gouv ?
Est-ce que schema.data.gouv est adapté à la diffusion de multiples tables reliées entre elles par un système relationnel, comme dans le cas du GTFS ? Sur schema.data.gouv le modèle table unique est le seul présent, j’ai l’impression.
En tout cas, merci Johan pour cette mine d’informations. Je découvre tout un monde avec frictionless
Qu’entends-tu par là ? schema.data.gouv.fr n’est qu’un catalogue de schéma. Il ne fait pas de « lecture » du schéma autrement que pour le présenter, sur la page documentation.html notamment (exemple). Cette documentation n’est qu’une traduction partielle et simpliste du schema.json sous une forme lisible par un humain et celle-ci s’appuie sur la librairie Python table-schema-to-markdown (à noter que nous avons également développé une implémentation en JS). Si ton Table Schema est conforme (et validé par la librairie frictionless-py), tu n’as rien à faire de plus.
Attention, encore une fois schema.data.gouv.fr n’est qu’un catalogue de schémas, et c’est Data.gouv.fr qui a vocation à cataloguer tes fichiers conformes à un schéma.
Quand on parle de données tabulaires* il s’agit de fichiers et non pas de bases de données relationnelles. Donc la notion de « table » n’a pas sa place dans l’open data. Même un GTFS ce ne sont que des fichiers CSV zippés ensemble.
Il ne suffit pas de faire une extraction de base de données pour faire de l’open data, et à l’inverse il ne sera jamais satisfaisant d’essayer de reproduire ce que permet une base de données relationnelle avec des fichiers CSV. Un fichier publié en open data a vocation à être lu et compris par un humain en se basant sur des connaissances universelles et indépendamment de tout contexte spécifique à un groupe ou une organisation, alors qu’une base de données est elle propre à un contexte métier, interne à une organisation.
En revanche, il y a des évolutions qui répondent peut-être en partie à ton besoin au sein des spécifications Frictionless Data, voir notamment les Foreign Keys dans Table Schema.
Mais à mon avis, cela a un sens pour des données dites « pivot » comme des identifiants officiels (code SIRET par exemple) mais pas pour lier des fichiers entre eux comme des tables d’une BDD.
Je sais qu’OpenDataFrance a une réflexion en cours qui ressemble à la tienne (voir par exemple le lien entre ce schéma et celui-ci) mais je ne suis pas convaincu de sa pertinence car cela risque de rendre très complexe la production et l’utilisation des données produites. Mais cela peut valoir la peine de tester !
* D’ailleurs, petite incise à ce sujet : « donnéees tabulaires » = fichiers CSV, TSV, avec virgule, tabulation ou point virgule, .ods et même Excel : peu importe. D’ailleurs par exemple Table Schema (et Frictionless) n’a aucune notion de séparateur, il travaille au niveau au-dessus, sur les données tabulaires et pas leur sérialisation CSV. C’est une très bonne chose pour simplifier la vie autant des producteurs que des utilisateurs des données qui n’ont plus à se préoccuper de ces questions pour eux futiles, et c’est bien ça l’objectif !
En fait, le cas est le suivant, pour lequel je me pose la question de relations. Une voie ou une partie de voie peut être soumise à plusieurs types de réglementations selon, par exemple, le type de véhicules.
Dans le modèle tabulaire, nous aurions alors ceci :
voie1,regl1,geom_voie1
voie1,regl2,geom_voie1
Dans ce cas, la géométrie de la voie est dupliquée en autant de lignes qu’il y a de règlements. Or, les champs geojson occasionnent de la lourdeur dans la table.
D’où la question de stocker dans une table la géométrie associée à chaque voie ou section de voie :
voie1,geom_voie1
voie2,geom_voie2
Cela dit, il se peut que l’on ne rencontre pas beaucoup de cas de n réglements pour une voie. Mais pour d’autres thématiques, on peut imaginer que la concentration en une seule table, et les redondances que celle-ci implique, peuvent être assez limitantes.
Merci pour toutes ces pistes : foreign key, etc…bien qu’en effet, il vaille mieux privilégier l’utilisabilité d’un fichier et d’un schéma. On préfèrera donc la création d’un seul fichier.
Dans mon cas, je prenais l’exemple de regl1 et regl2 par facilité, mais en réalité regl1 se déclinerait en de multiples colonnes qui définissent les différentes caractéristiques des autorisations ou interdictions associées à l’arrêté (type de véhicules VEH_TYPE, d’usages VEH_USAGE ou périodes horaires PERIODE_HORAIRES,…).
Certes, on pourrait, au lieu d’avoir une colonne avec geom_voie1, stocker les identifiants des voies tels qu’ils sont dans les référentiels (osm_id par exemple pour OSM) mais, d’une part, cela reste soumis à la stabilité des identifiants (risqué), d’autre part, surtout, parfois, ce sont des sous-parties de voies qui sont concernées.
En aparté, j’ai remarqué que la création d’identifiants id n’était pas forcément courante dans les schémas publiés sur schema.data.gouv.fr
Au final, je pense qu’on restera probablement sur de la donnée « aplatie », à moins de partir sur des foreign keys, mais je n’en suis pas convaincu car il faut privilégier la lisibilité et la réutilisabilité, d’autant plus qu’on n’aura peut-être pas autant de redondances que ça.
Ce que je me demandais, c’était si, en implémentant le type array dans mon schéma, ce dernier serait bien documenté sur la page documentation.html dans la mesure où il s’agit, je crois, d’une spéc’ assez récente de tableschema.
En tout cas, je pense avoir suffisamment d’éléments pour avancer. Aussi, je vous remercie pour les orientations que vous avez pu me donner.
Ce travail, réalisé par le Cerema, en partenariat avec La Région Sud et l’association OpenDataFrance, intervient dans le cadre de réflexions menées lors de la Fabrique de la Logistique, et d’une convention avec La Région Sud, au sujet de la dématérialisation des arrêtés de circulation et la publication de jeux de données relatifs à ces arrêtés sur le portail DataSud.
Il rejoint une initiative similaire conduite en Île-de-France, appelée BAC IDF visant à concentrer, numériser et mettre à disposition les arrêtés de circulation pour la logistique en ville.
Après pas mal de tâtonnements : création d’un environnement de saisie sous logiciel SIG, la publication d’un schéma sur schema.data.gouv.fr nous a semblés la meilleure option, notamment car celle-ci fait éclore automatiquement une myriade de solutions, à savoir un validateur de données et un éditeur de données de qualité en ligne.
Vous trouverez sur la page du schéma des tutoriels de création de données ainsi que des exemples de fichiers saisis selon ce schéma.
Le schéma vient accompagné d’un assistant (groom-groom) qui permet au quidam de récupérer la chaîne Opening Hours relative aux jours et heures de circulation autorisés (ou interdits), ou la géométrie de rues sur lesquelles s’applique une règlementation de la circulation.
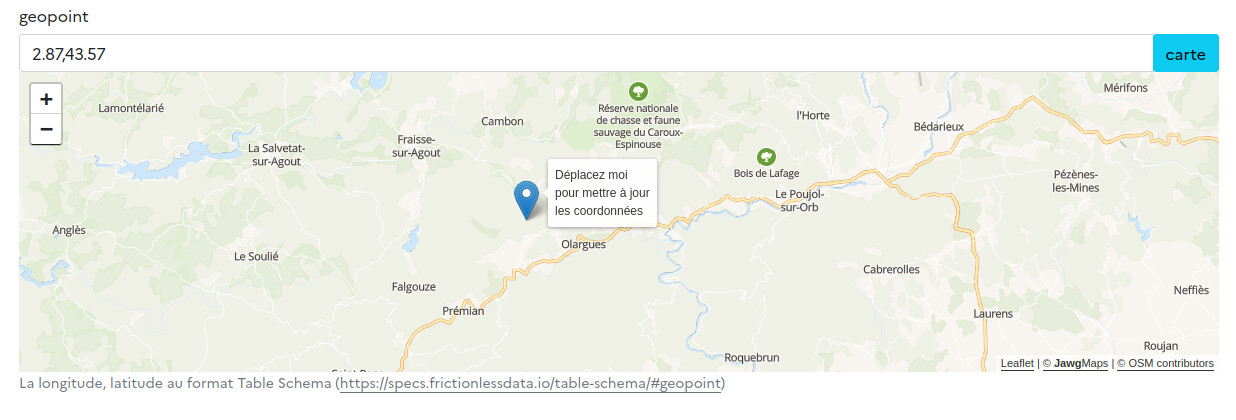
Dans le schema, une erreur sur l’exemple avec coordonnée GPS… le description dit long,lat et l’exemple utilise lat,long
Il est vraiment dommage d’avoir mis ces coordonnées dans un champ texte descriptif, vraiment une drôle d’idée alors que je vois qu’il y a un champ WKT complet.
Dommage pour l’ID qui ne garantit pas d’unicité globale, mais locale, un ID composé du code INSEE de la collectivité + N° d’arrêté + partie unie aurait été bien plus intéressant pour l’agrégation.
Pour les coordonnées GPS, tu mentionnes le champ EMPRISE_DEBUT et EMPRISE_FIN. Ces champs désignent les extrêmités de la voie sur laquelle s’applique la règlementation. Car un règlement peut s’appliquer seulement à une portion de voie, et non à la voie entière. EMPRISE_DEBUT et EMPRISE_FIN peuvent à la fois contenir du texte (intersection de rue xxx et rue yyy) ou des coordonnées GPS. Le plus souvent, ces informations sont textuelles dans les arrêtés, et il peut être assez compliqué pour un opérateur de récupérer les coordonnées GPS de ces extrêmités. Néanmoins, s’il y parvient, rien ne l’empêchera de les renseigner dans EMPRISE_DEBUT et EMPRISE_FIN (une regex permettrait de savoir si description textuelle ou coordonnées GPS).
Concernant le champ GEOM_WKT : dans le meilleur des cas, ce champ est rempli, mais il peut difficilement remplacer les champs EMPRISE_DESIGNATION, EMPRISE_DEBUT, EMPRISE_FIN. Sans doute, la majorité des producteurs de données saisiront des informations textuelles dans EMPRISE_DESIGNATION, EMPRISE_DEBUT, EMPRISE_FIN, d’après les informations contenues dans les arrêtés, et ne mettrons pas la géométrie directement dans GEOM_WKT, car cela demande une certaine technicité.
Le géoréférencement (remplissage de GEOM_WKT) peut intervenir par la suite, dans une seconde passe, en s’appuyant sur les informations renseignées dans MPRISE_DESIGNATION, EMPRISE_DEBUT, EMPRISE_FIN. En tout cas, c’est comme cela que nous imaginons les choses, mais cela reste discutable
Pour l’ID, nous avons proposé, dans la description, d’utiliser heidi d’Etalab pour garantir l’unicité globale, et faciliter le remplissage des identifiants.
Je comprends bien, mais inclure dans un champ textuel des données dans un format non définit (il n’y a pas de regexp de validation de la façon d’insérer ces coordonnées), c’est être à peu près sûr d’avoir n’importe quoi au final et donc inutilisable. Ajouter deux champs lat/lon debut/fin serait quand même bien plus carré.
Oui, donc pour espérer avec quelques chose de géographique, il faudra croiser les doigts pour que ça se trouve quelque part et pas trop mal formatté dans un champs en texte libre… inutilisable dans la majorité des cas.
Là tu décris un process métier, si possible interne… c’est pas tellement le but d’un schema.
Oui, une sorte d’UUID qui n’en est pas un, mais comme rien ne l’impose ça n’a au final pas grand intérêt qu’il soit unique. Je ne saisit même pas l’intérêt de « heidi », il y a une API pour les récupérer automatiquement lors d’un traitement ou c’est juste un clicodrome ?
Un UUID (lié au hardware via l’adresse MAC pour ceux version 1 ou 2 sauf erreur) permet d’avoir une unicité globale.
Il y a de nombreuses librairies logicielles qui permettent de les générer et c’est même définit par une norme ISO et surtout un RFC 4122 (libre lui !).
Dans une précédente version du schéma, nous avions inclus deux champs GEOM_DEBUT et GEOM_FIN au format geopoint pour ces débuts et fin, en plus des champs textuels, mais les avions abandonnés afin de rendre le schéma plus léger. Était-ce une bonne idée de les enlever ? Peut-être pas.
Nous avons essayé de trouver un bon équilibre entre niveau technique requis pour produire la donnée et l’exigence de qualité nécessaire pour certains champs.
Dans tous les cas, les arrêtés existants ne font le plus souvent pas mention de coordonnées GPS, mais de mentions d’intersections, de carrefours qu’on ne peut omettre dans la donnée finale au format texte.
Il n’est pas que métier. Il est fonctionnel. Si le producteur ne peut saisir la géométrie de la rue dans GEOM_WKT sachant que les raisons peuvent être multiples (information imprécise, lacunaire, défaut de technicité), il pourra malgré tout saisir les informations de façon textuelle dans les trois champs EMPRISE_DESIGNATION, EMPRISE_DEBUT, EMPRISE_FIN.
Supprimer les champs EMPRISE_DESIGNATION, EMPRISE_DEBUT, EMPRISE_FIN me semble assez dangereux, et exiger en même temps GEOM_WKT freinerait la production de données. Règlementairement, je pense qu’il est indispensable de conserver les informations textuelles associées à la voie règlementée.
Et supprimer la colonne GEOM_WKT serait dommage, mais sans doute moins critique. Est-ce que cela vaudrait le coup de supprimer la colonne GEOM_WKT, d’après ce que tu dis ? Je suis assez mitigé.
Concernant le côté texte libre, il y a quand même une regexp censée contrôler si la ligne respecte le format WKT*.
Heidi est l’outil que l’équipe de schema.data.gouv.fr nous a conseillés. Son code source est ici. Nous nous sommes beaucoup questionnés sur cet ID. Je vais davantage me renseigner sur le format uuid, d’ailleurs inclus dans TableSchema. Mais un uuid pourra-t-il selon toi être facilement rempli par un opérateur après interprétation et numérisation d’un arrêté PDF ?
Je te remercie pour tes réponses. N’hésite pas à réagir. Je trouve cet échange très intéressant et constructif
*En aparté, je pense qu’il serait tout à fait utile que les outils d’édition intègrent une dimension saisie géo : de point, de ligne, de surface.
Il y a déjà tellement de champs optionnels, qu’on n’est plus à 4 champs près. 4 car il vaut mieux à mon avis avoir un champ lat_debut, lon_debut, lat_fin, lon_fin (qui ne sont que des nombres décimaux) qu’un « geopoint » assez éloigné d’une saisie dans un tableau/tableur/CSV et bien plus proche d’un SIG qui lui pourra en principe sortir le WKT de la voie.
Pour le WKT, c’est très bien et je n’ai pas suggéré (où à l’insu de mon plein gré) la suppression des champs textuels EMPRISE_xxx.
Pour le WKT, oui il y a une regexp, c’est pour les champs libres où il est suggéré de mettre les long/lat que c’est sans filet.
Restaurer les 2 champs geopoint initiaux ou 4 champs décimaux : mon coeur balance…
Je fais le pari que les outils d’édition en ligne comme D-Lyne et publier.etalab.studio proposeront automatiquement, sur la base de cette formulation geopoint, des outils d’édition cartographique avec saisie de point pour ces champs (en fait, c’est déjà le cas pour D-Lyne).
Aussi, le format geopoint intègre de lui-même des contraintes de formatage propres aux coordonnées GPS tout en indiquant par son format la nature de l’information renseignée (géographique, de localisation).
La façon de formater ces champs pourra apparaître dans les exemples ou descriptions de champs. Aussi, je suppose qu’une personne qui sait remplir des colonnes long et lat d’un tableau sera en mesure de remplir une colonne unique long,lat
D’un autre côté, séparer long et lat permet sans doute un retraitement plus facile des champs sous un logiciel SIG. Nous allons peser le pour et le contre de chaque solution
Le côté universel d’uuid est intéressant. Malgré tout, l’outil uuid.online étant en anglais, je préfèrerais l’outil Heidi qui présente les mêmes fonctionnalités (excepté la génération d’uuid), mais en français, sachant que la langue française est un prérequis pour certains profils qui produiront des données.
Enfin, je pense qu’il n’y aura pas trop de risques de doublons avec Heidi, à l’échelle nationale, étant donnée l’allure des ID qu’Heidi produit, ex. 01FF5GKXXGWM2T55XRM3RX9ZHN
Merci beaucoup pour toutes ces remarques grâce auxquelles il y aura sans aucun doute une évolution du schéma, notamment la restauration des champs géométriques EMPRISE_DEBUT_POINT et EMPRISE_FIN_POINT ou la création de champs EMPRISE_DEBUT_LONG, EMPRISE_DEBUT_LAT, EMPRISE_FIN_LONG, EMPRISE_FIN_LAT
Ne pas hésiter s’il y a d’autres remarques ou d’autres idées !
Les outils d’édition évolué permettront tout aussi bien de remplir 2 champs.
Les outils non évolué (les plus utilisés, non ?), seront bien content d’avoir 2 bêtes champs numériques.
Pour l’UUID, j’ai mis le premier lien d’un site trouvé il y en a forcément un en français… et c’est un truc qui doit se coder en une heure maxi si besoin de souveraineté.
Les « Heidi » complètement exotiques alors qu’une norme existe en la matière sont une erreur de mon point de vue.
Dans D-Lyne, il y a un petit widget qui permet de rechercher une adresse pour se positionner. Aussi, dans D-Lyne, on peut saisir des surfaces, des lignes, il me semble. A tout hasard, sais-tu si l’édition carto s’active pour ligne/surface/point dans publier.etalab.studio dès lors que le champ est de type geojson ?