Les étudiants ont défini la forme des livrables finaux qu’ils vous présenteront vendredi. Pour qu’ils puissent s’assurer que ceux-ci répondent à votre demande, nous vous les soumettons par le présent message.
Pouvez-vous leur faire un retour pour qu’ils puissent préciser/réorienter ces livrables ?
Livrable 1 : modélisation d'une aide automatique au recrutement
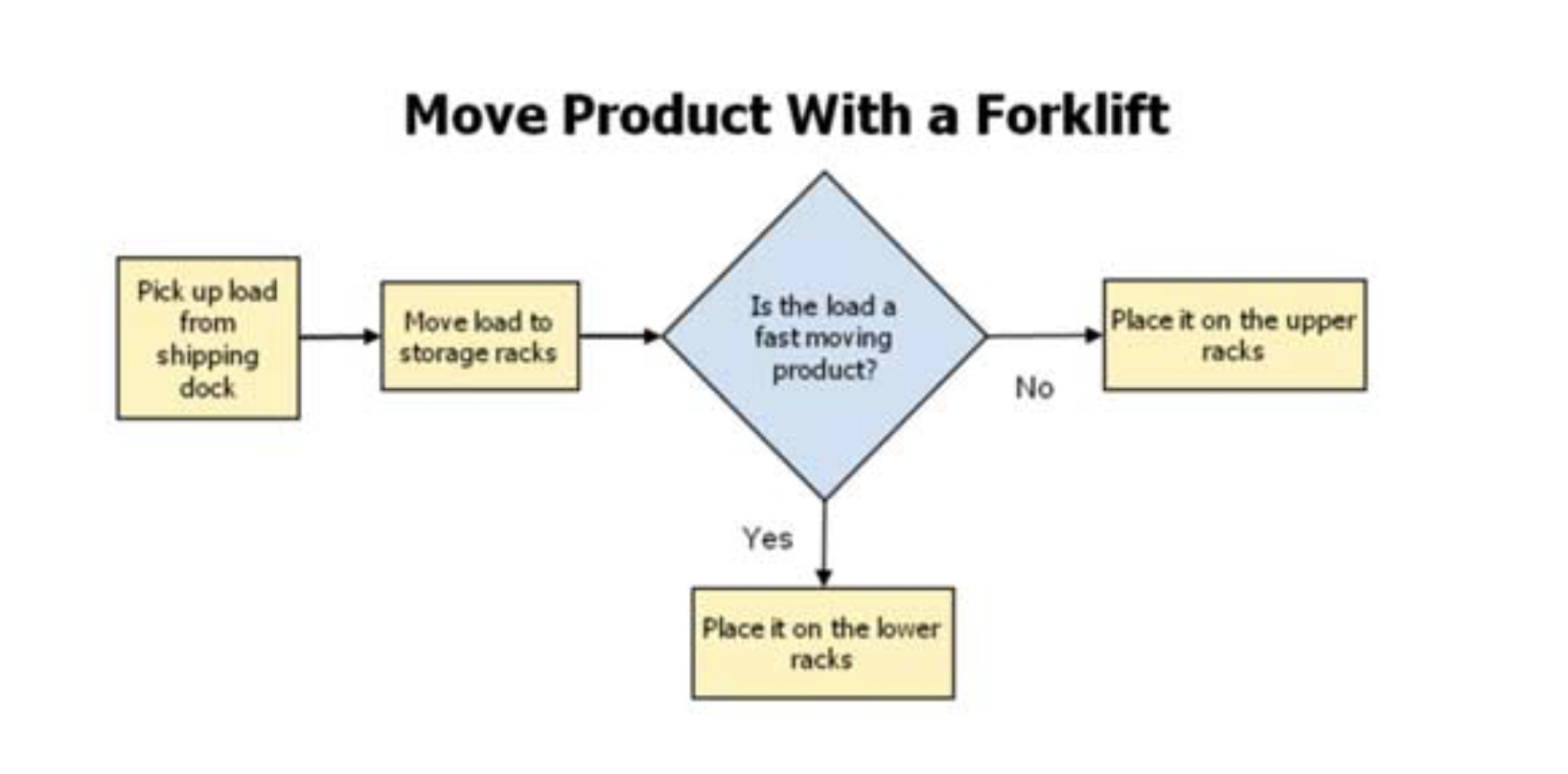
Les étudiants ont commencé par modéliser le parcours de recrutement d’un nouvel agent dans la fonction publique territoriale, tel qu’il existe aujourd’hui. Ce parcours prend en compte 3 persona types : les DRH, les directions métiers et les candidats. Sur la base de ce parcours, nous sommes en train d’identifier/distinguer 2 types de tâche dans ce parcours :
-
Les tâches cognitives/tacites (non-observables) effectuées par les DRH : compréhension du besoin de recrutement des métiers, pré-analyse des CV reçus, analyse des entretiens --> ce sont ces tâches qui seront assistées/remplacées par l’analyse de données effectuée par l’algorithme de matching
-
Les tâches pratiques/explicites (observables) effectuées par les DRH & Directions métiers & Candidats : création de la fiche de poste, création d’un CV réalisation des fiches d’évaluation des entretiens d’embauches --> ce sont ces tâches qui vont créént de la donnée et alimenter l’algorithme de matching. Exemple : au lieu de créer une fiche de poste sous un format PDF, un DRH & Direction métier devront remplir un questionnaire qui créera automatiquement un jeu de données « OffresEmploi » duquel se nourrira l’algorithme
Exemple de modélisation d'une activité (losange --> tâche cognitive // rectangle --> tâche pratique)
Livrable 2 : data-ification des offres d'emplois et des CVs
La recherche de CVthèque ou d’Offres d’emplois en Open Data s’étant avéré infructueuse (mais @ldarras, vous pouvez peut-être obtenir un export des offres d’emplois présentes sur Weka jobs ?), nous avons décidé de data-ifier les CVs et offres d’emplois transmis par la métropôle de Nantes.
Pour cela, nous allons tagger les documents transmis et exporter le résultat des activités de tagging pour créer des jeux de données. Ainsi, nous pourrons fournir 2 jeux de données : 1 jeu qui catégorise les éléments textuels présent dans les offres d’emplois (Jeu OffreEmploi") et 1 jeu qui catégorise les éléments textuels présents dans les CVs (Jeu « CVThèque »). Ci-dessous un aperçu du jeu de donnée que nous pourrions créer.