Je partage ici une traduction/vulgarisation que j’ai faite d’un article de recherche que j’ai effectué pour expliquer à des étudiants de SciencesPo Grenoble tout le travail technique nécessaire avant qu’un jeu de donnée puisse réellement devenir/aider une innovation de services :
Lien vers le billet par ici // Lien vers le schéma explicatif par là
Je fais appel à la communauté pour savoir si vous connaissez d’autres modèles qui permettrait d’expliquer simplement le travail invisible de la data qui sous-tend le design de nouveaux services.
Merci @ArthurSz pour le partage. Le modèle en séquences permet effectivement de décomposer les différentes étapes et tâches requises pour valoriser des données (ouvertes) sous la forme de services. Il donne à voir les recettes utilisées dans l’arrière-cuisine de la réutilisation. Toutes les séquences ne sont toutefois pas systématiquement observables dans les pratiques (la 4eme par exemple). Je me demande dans quelle mesure la 1ere est impactée par le travail invisible réalisé en amont par les producteurs mettant les données à disposition (mise en qualité et standardisation). D’ailleurs, connaitrais-tu un modèle qui permettrait d’expliquer simplement ce qui ce passe dans l’arrière-cuisine de la production de données (ouvertes) ?
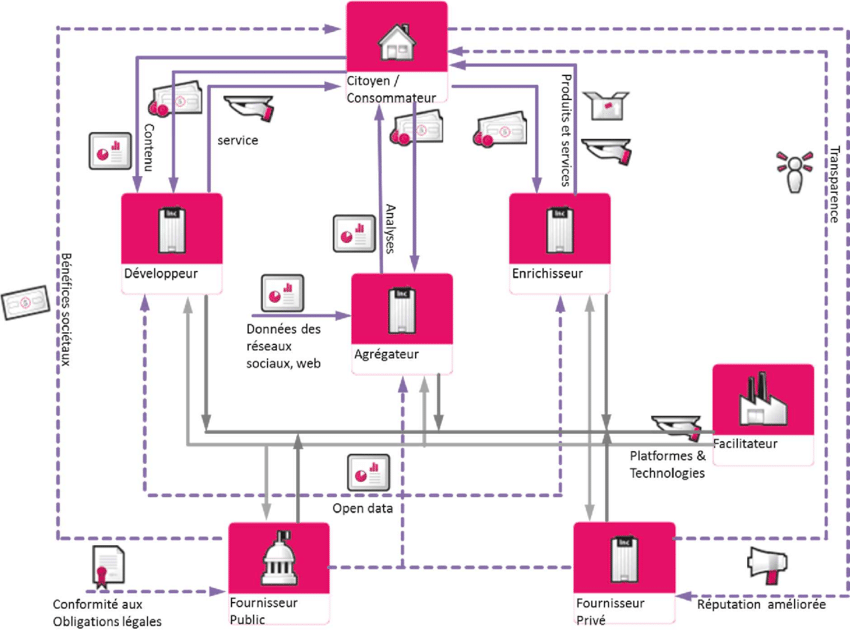
Moins détaillé et procédural, l’Open Data Value Chain Archetypes est un autre modèle explicatif plus orienté sur le jeu des acteurs et la définition de profils de réutilisateurs :
Merci de tes retours. J’essaye justement de définir qui s’occupe de quoi à présent. Pour l’instant, je partirai sur la base de 3 rôles : producteur, intermédiaire et réutilisateur. Je creuse la littérature scientifique sur ces rôles pour essayer d’aboutir à des définitions précises. Si tu as de la doc là-dessus, je suis preneur.
Il y a une vraie question sur la première étape. A chaud, je dirai que la mise à dispo d’API est assez régulièrement prise en charge par des intermédiaires comme Open Data Soft ou des autres vendeurs de logiciels. Je sais pas ce que tu en penses.
Et sur la 4ème étape, je suis d’accord. Ca impliquerait qu’open data = solutions open source. Ca serait idéal mais à mon sens peu réaliste.
Cette Open Data Value Chain est merveilleuse. De quelle source provient-elle ?
Pour les modèles, celui que j’utilise dans l’article (objet de mon post initial) est le plus simple que j’ai rencontré pour l’instant.
Sinon je pense à l’échelle de qualité des données ouvertes de Tim Berners Lee mais ce n’est pas un modèle d’activités séquentielles à proprement parler…
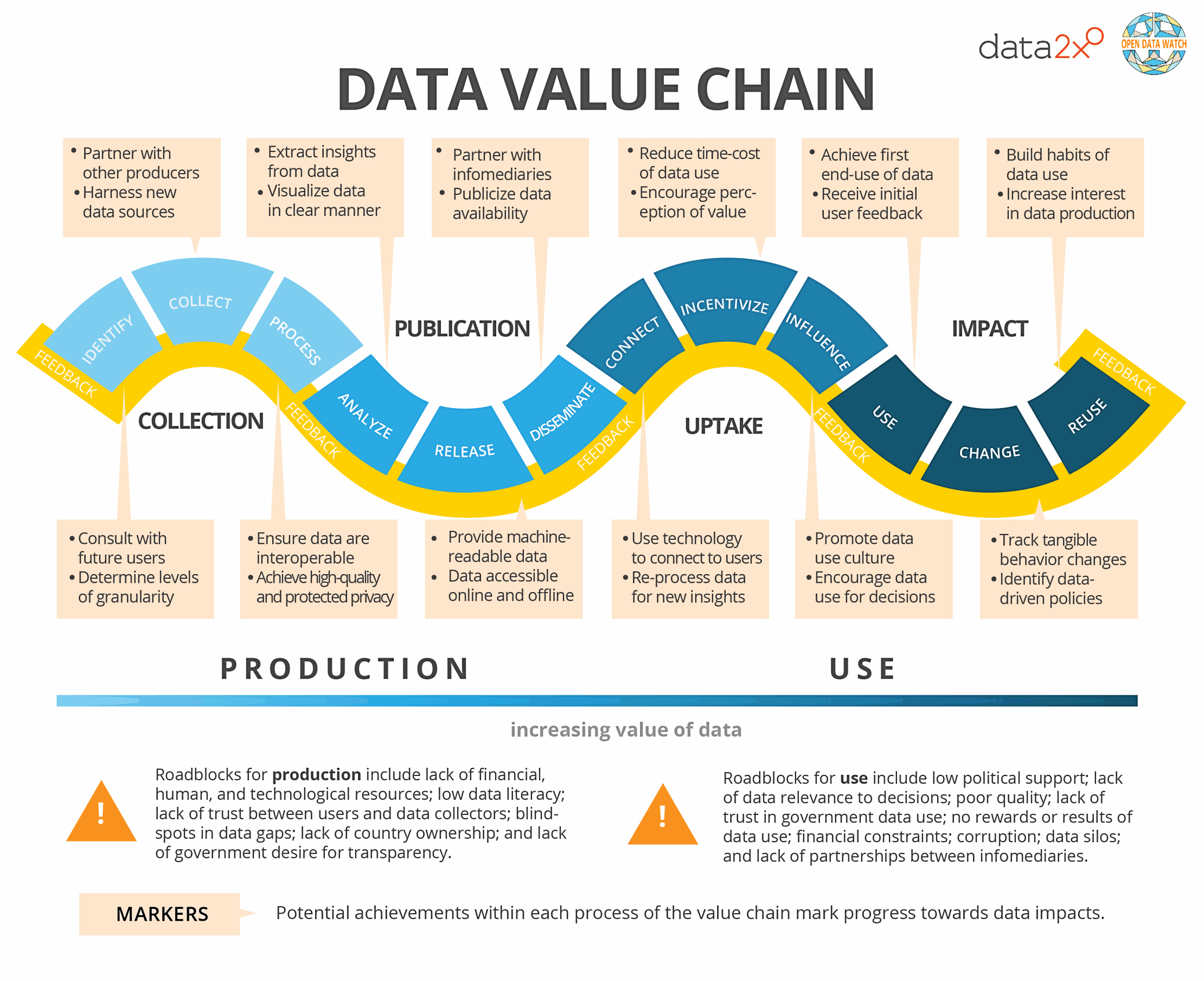
En 2018, Open Data Watch a publié « The Data Value Chain: Moving from Production to Impact » qui explique également l’ensemble des maillons de la chaîne de valorisation entre production et usage des données. Ils en ont fait un joli schéma
Top ! A mon tour de les comparer et merci pour les références
A mon sens, la meilleure façon d’activer ces schémas seraient de s’en servir comme la base d’un parcours utilisateur d’un outil digital qui viendraient soutenir les collectivités dans leurs démarches open data.
C’est d’ailleurs un point que je souhaiterai évoquer avec @CharlesNepote, @joel et @samgoeta dans le cadre du développement de l’Open Data Canvas