Le site (très joli) est en ligne : http://www.observatoire-opendata.fr/
V0 (mars 2018) : prototype de l’Observatoire
C’est le site actuel : http://www.observatoire-opendata.fr/
@loichay a présenté les premiers indicateurs : http://slides.com/loichay/resultats_v0, ma synthèse :
- 4411 collectivités concernées par la loi Lemaire
- 257 ont ouvert des données
- 33% des départements et 66% des régions ont déjà ouvert des données, 68% des métropoles
- 22k jeux de données publiés, croissance très forte depuis 2015
Les données brutes de ces chiffres seront publiés en open data en avril 2018.
V1 (octobre 2018) : Observatoire opérationnel
Le modèle de données sera consolidé, intéressant de voir qu’il y aura des données d’usage.
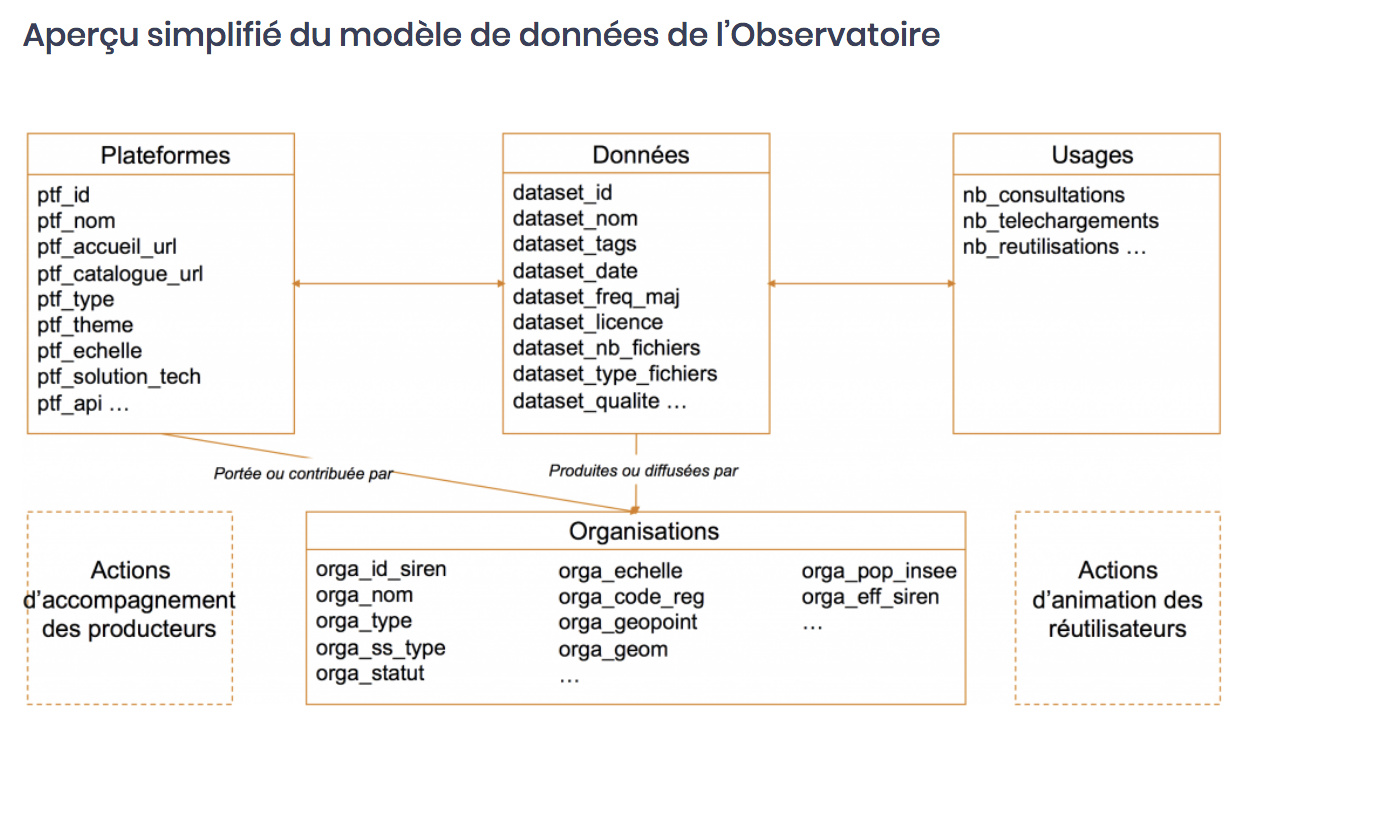
L’outi de collecte, de stockage et de traitement des données sera consolidé puis élargi à d’autres types d’acteurs territoriaux, essentiellement les intercommunalités. Une enquête par questionnaire sera réalisée pour compléter le recueil automatisé (par Sciences Po, chaire « villes et numérique » dont @acourmont est le responsable).
Un outil de visualisation dynamique des principaux indicateurs sera produit.
Edition annuelle de l’Observatoire : restitution et analyse régulière à partir de début 2019
Voici les indicateurs retenus pour le moment :

Je me pose trois questions @jmbourgogne @loichay :
- Est ce que les données agrégées de tous les catalogues de données (les metametadata) seront ouvertes ? Dans ce cas, ça nous sera très utile pour le travail qu’on va conduire avec @mathieu sur la semi-automatisation du recensement.
- Comment allez vous faire pour moissoner les catalogues ? Data.gouv.fr peine déjà à le faire et on s’est rendu compte que beaucoup de portails n’ont même pas cette fonctionnalité. Est-ce que vous allez faire du scrapping?
- Comment comptez vous collecter les statistiques d’usage ? C’est vraiment très intéressant comme données mais il peut y avoir un gros boulot pour rassembler ces données. On l’avait fait pour data.gouv.fr avec les statistiques de fréquentation quotidienne par URL du site (données et code). En tout cas, ces données sont essentielles pour éviter qu’on se concentre trop sur le nombre de jeux de données ouverts ce qui ne dit pas grand chose de l’utilité des données ouvertes.
En tout cas, le projet s’annonce très intéressant !



 non prévu au départ).
non prévu au départ).