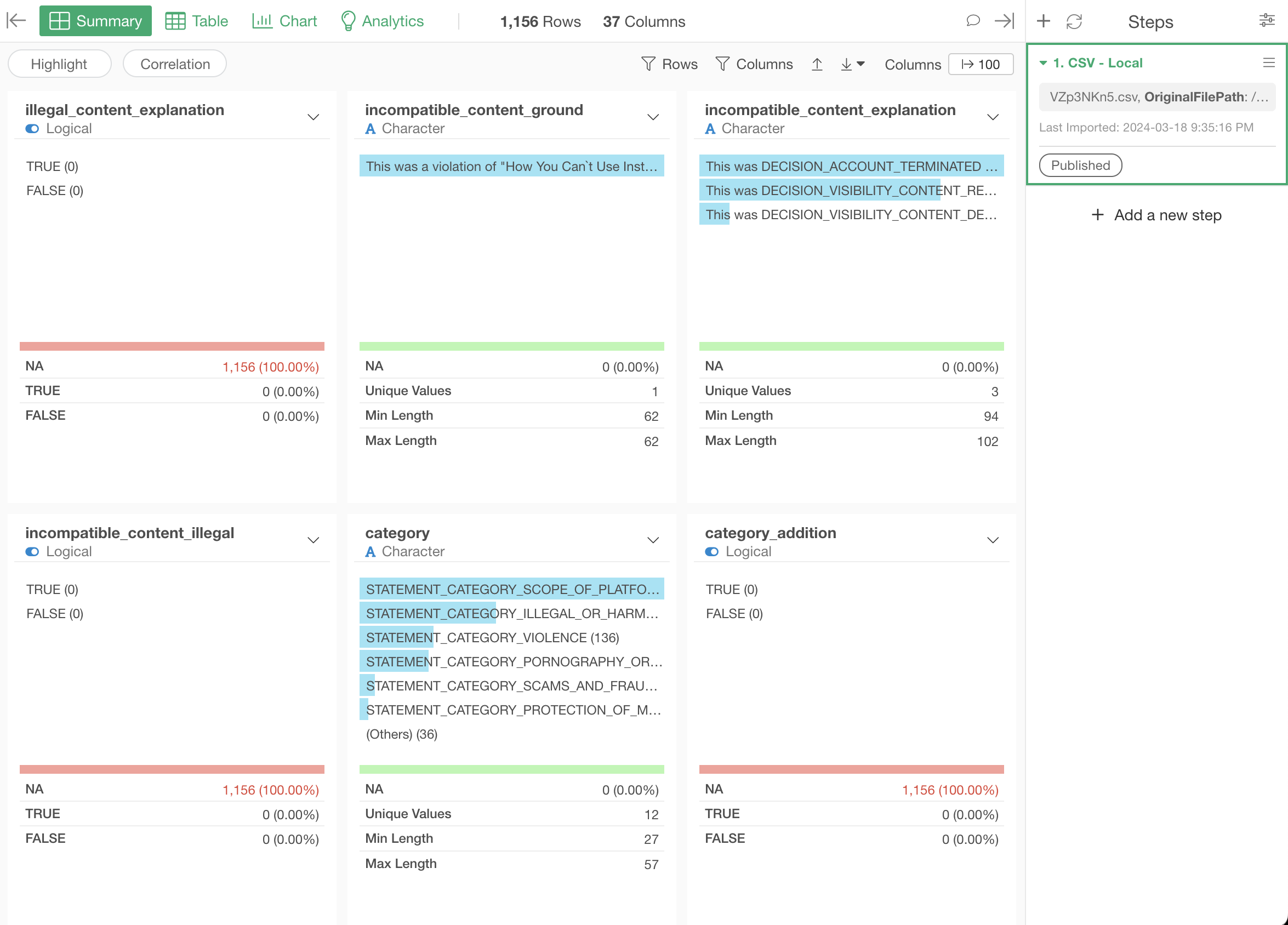
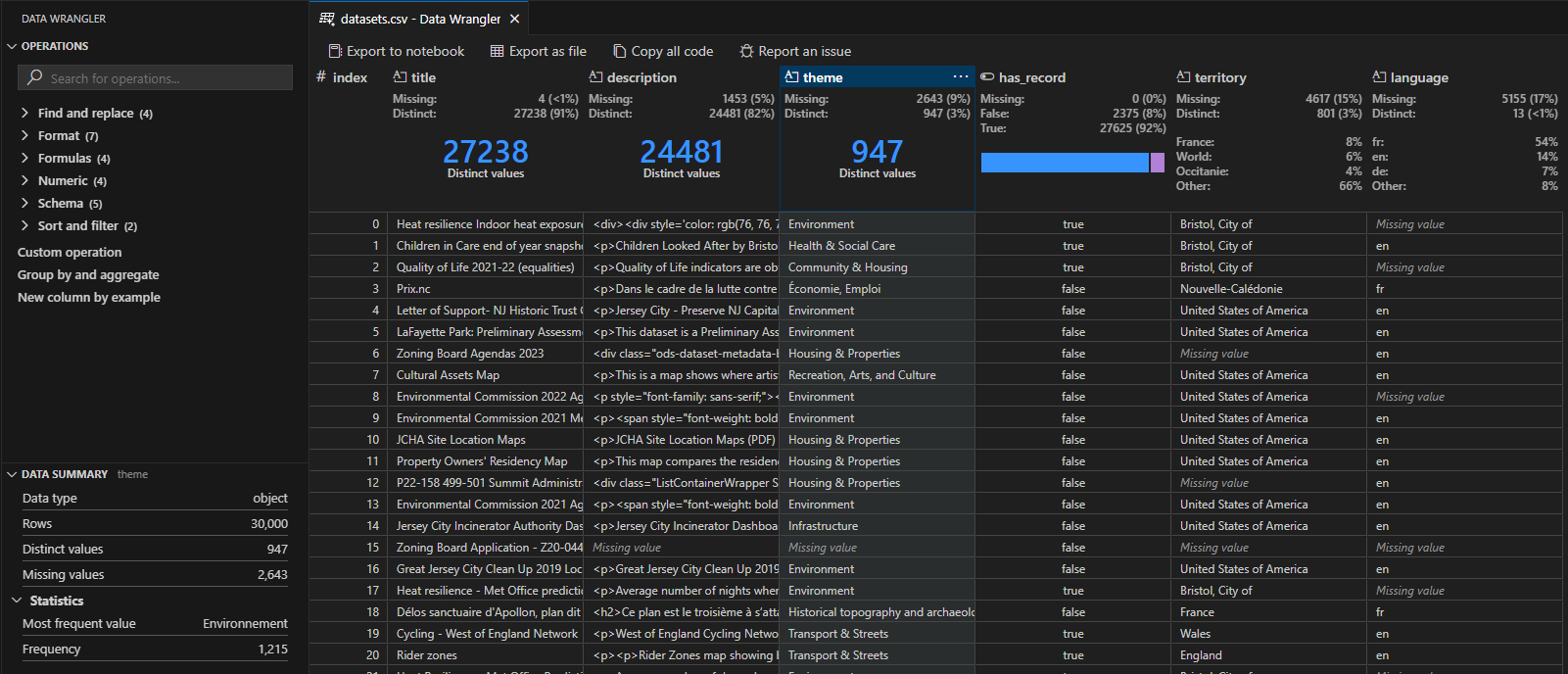
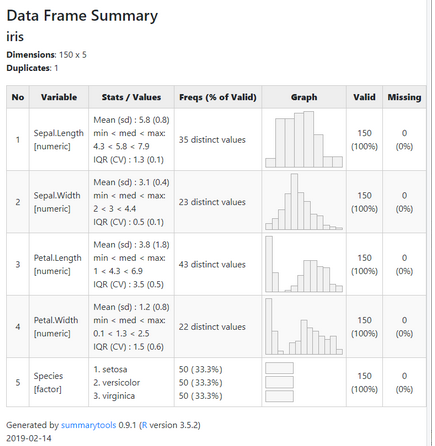
Vous vous souvenez WTFcsv, conçu par Rahul Bhargava et Catherine D’Ignazio, présenté au public français à Data Literacy Conference en 2018 ? Il s’agit d’un petit outil permettant d’explorer très rapidement le contenu d’un fichier CSV à travers de petits graphes ou des données statistiques. Idéal pour explorer rapidement un jeu de données open data.
J’ai toujours apprécié cet outil mais il a plusieurs défauts qui freinent son usage :
- il ne gère pas bien les différentes formes de CSV (points-virgules, TSV, etc.)
- c’est un outil SAS hébergé je ne sais où, je ne lui confierais pas de fichiers hors open data
- enfin, il ne peut pas ouvrir de gros fichiers
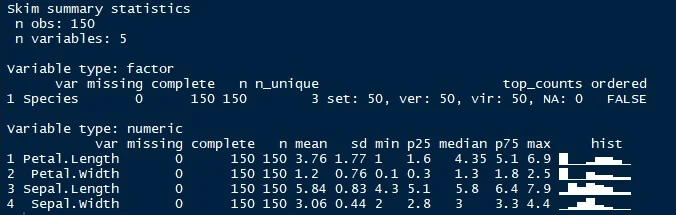
Pour toutes ces raisons, et comme je suis un fan de Datasette, j’ai créé csv2datasette, un petit script en bash qui permet d’ouvrir un fichier directement dans Datasette, avec la possibilité d’obtenir automatiquement des stats pour chaque colonne : « the column name, the number of unique values, the number of filled rows, the number of missing values, the minimum value, the maximum value, the median, the 10th, 25th, 50th, 75th and 90th centiles, the average, the sum, the shortest string, the longest string, the number of numeric values, the number of text values, the number of probable ISO dates, the top 3 frequent values ». Pratique pour bien comprendre le contenu de chaque colonne : les manques, les valeurs aberrantes, etc.
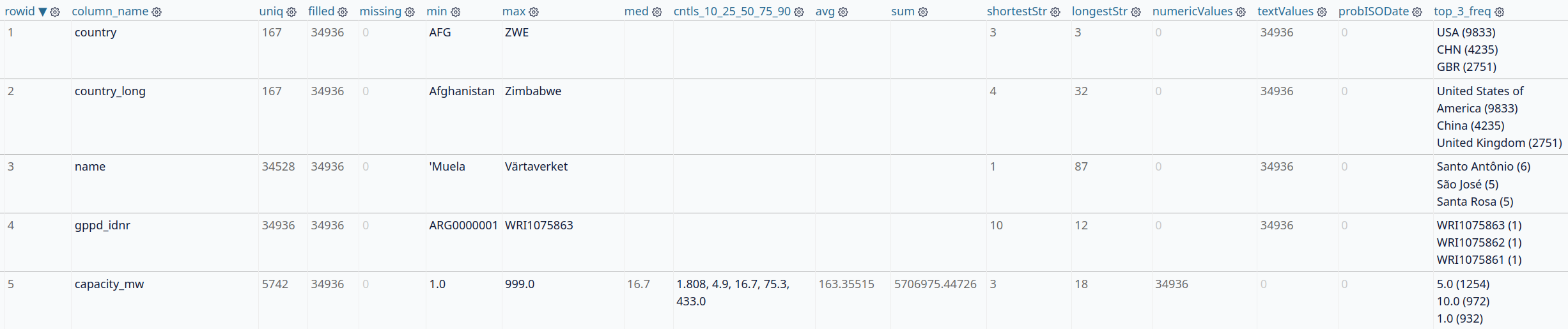
Une fois le CSV chargé, vous profitez de toutes les fonctionnalités de Datasette qui vous permettent d’aller assez loin dans l’exploration, avec son interface utilisateur simplifiée ou directement en SQL.
C’est assez modeste, le design est discutable, le truc est un peu trop geeky (il faut installer Datasette, plus l’extension REGEXP pour SQLite) et testé seulement sous Linux, mais passé toutes ces barrières, c’est un outil qui peut peut-être vous faire gagner du temps si vous avez l’habitude d’explorer des fichiers CSV.
Comme il m’est très utile, je me suis dit qu’il pourrait en intéresser certains ici.
Et vous, qu’utilisez-vous en pareil cas ?