Bonjour à tous et à toutes,
J’ai préparé une « issue » pour faire évoluer le standard Table schéma (cf relationship_property.pdf) et je souhaite avoir au préalable votre avis sur la pertinence de cette évolution :
Je travaille depuis pas mal de temps sur la notion de « liste indexée » (cf présentation Ilist_technical.pdf) et il se trouve que cette notion est adaptée aux fichiers tabulaires (CSV) que l’on retrouve majoritairement dans les données partagées.
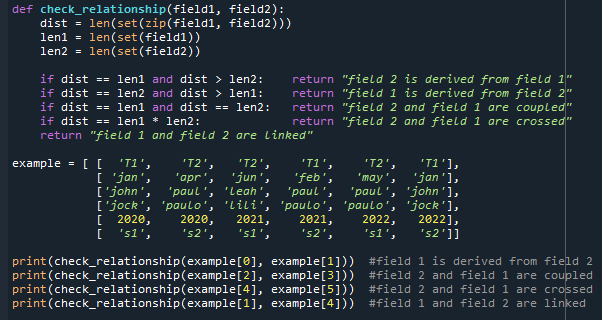
Cette notion permet notamment de définir les liens entre champs d’un fichier tabulaire et de contrôler que ces liens sont bien respectés. Quatre types de liens sont définis :
- « coupled » : équivalent à une relation 1-1 dans un MCD (ex.lien entre une personne et un n° de sécurité sociale)
- « derived » : équivalent à une relation 1-n dans un MCD (ex. lien entre un trimestre et plusieurs mois)
- « crossed » : relation n-n avec tous les liens (ex.lien entre élève et matière scolaire dans le bulletin de note d’une classe : chaque élève a une note dans toutes les matières, chaque matière est controlée pour tous les élèves)
- « linked » : pour tous les autres cas.
Ce type de relation entre champs peut être facilement mesuré et contrôlé (également à la saisie), c’est pourquoi je propose de l’ajouter dans les propriétés du standard Table Schéma.
A titre d’exemple, j’ai fait un test sur un des jeux de données disponibles sur data-gouv (j’ai pris celui des bornes de recharge, cf détail du test ici : test_IRVE.html) ) et les résultats me
semblent tout à fait intéressants :
- sur les 49 champs qui composent le fichier, seuls 6 champs sont de type « derived » et 1 de type « coupled » alors que la mesure du taux de couplage entre champs montrent que la grande majorité devrait être de type « derived » ou « coupled »,
- Par exemple, les champs ‹ consolidated_longitude › et ‹ consolidated_latitude › sont bien dérivés du champ ‹ coordonneesXY › (ce qui est tout à fait cohérent)
- Par contre, les champs ‹ coordonneesXY › et ‹ nom-station › devraient être liés et on observe que pour 1% des données, ce n’est pas le cas. Par exemple, pour la position [1.106329, 49.474202], on trouve 10 stations [‹ SCH01 ›, ‹ SCH10 ›, ‹ SCH09 ›, ‹ SCH07 ›, ‹ SCH06 ›, ‹ SCH05 ›, ‹ SCH04 ›, ‹ SCH03 ›, ‹ SCH02 ›, ‹ SCH08 ›] et pour la station ‹ Camping Arinella › on trouve 5 positions: [’[9.445075, 41.995246]’, ‹ [9.445074, 41.995246] ›, ‹ [9.445073, 41.995246] ›, ‹ [9.445072, 41.995246] ›, ‹ [9.445071, 41.995246] ›]. Ceci est peut être dû à une confusion entre stations de recharge et bornes de recharge.
Cet exemple montre que cette information de lien entre champs est importante pour l’exploitation ultérieure des données (sinon, comment positionne t’on les stations sur une carte si une station a plusieurs positions ?)
Afin de me conforter sur l’intérêt de l’ajout d’une propriété « relationship » dans Table Schéma, est-ce que vous pouvez me donner votre retour :
- est-ce que ça vous semble une bonne idée et est-ce nécessaire ?
- est-ce que vous avez été confronté à des difficultés d’exploitation de données parce que les relations entre champs n’étaient pas bien définies ou mal contrôlées ?
- dans les cas où cela est spécifié et contrôlé, quels étaient les outils utilisés pour le spécifier et le contrôler ?
Merci par avance pour votre retour (je mets également les fichiers en lien dans le corps du texte en PJ)
Bonne vacances pour ceux qui partent et bon courage pour ceux qui reviennent !!
test_IRVE.html (323,0 Ko)
relationship_property.pdf (164,6 Ko)
Ilist_technical.pdf (845,2 Ko)