On me demande souvent la position d’ODF au sujet de l’open data servi par des API. Est-ce une bonne pratiques ? ne cache-t-elle pas la volonté de contrôler in fine l’accès ? ne réduit-elle par l’open data à la création de service au détriment de l’information des citoyens (qui ne maitrisent pas l’informatique et les API) ?
J’ai bien conscience que les API permettent de répondre à des contraintes de diffusion liées 1/aux changements fréquents d’état (charge d’un parking, horaire, etc), 2/de gros volume de données (extraction à la volée sur un périmètre fonctionnel ou géographique), 3/contrôle de trafic trop important dans le cas de données temps-réel.
Mais systématiser l’approche API fait perdre l’esprit de fond de l’open data : l’ouverture brute, entière et sans contraintes d’accès.
Qu’en pensez-vous ?
Je lis à ce sujet une dernière publication de l’Europe sur PSI, l’API est mis à l’honneur… qu’en faire ?
https://translate.google.fr/translate?hl=fr&sl=auto&tl=fr&u=https%3A%2F%2Fwww.consilium.europa.eu%2Fen%2Fpress%2Fpress-releases%2F2019%2F02%2F06%2Feu-boosts-its-data-economy-as-council-approves-deal-on-wider-reuse-of-publicly-funded-data%2F%3Futm_source%3Ddsms-auto
En attendant que je finalise un de ces jours mon article “les API c’est bien, en abuser ça craint”, voilà quelques éléments issu de mon expérience.
Pour moi les API se justifient dans certains cas:
- données volumineuses
- données changeant très vite
- accès contrôlé au cas par cas à des données (donc pas ouvertes et donc hors sujet)
Le cas typique pour le 1°: les photos aériennes… plus simple à utiliser via une API “flux” pour beaucoup de monde, mais ça n’empêche pas de les proposer aussi en téléchargement.
Pour le 2°… les données temps réel des transport… et encore, un GTFS-RT ça va très bien aussi
Avantage des API:
- le réutilisateur accède à un service qu’il n’a pas à mettre en oeuvre lui même… c’est souvent du confort à court terme

^ aidez moi à en trouver d’autres ^
Inconvénients:
- dépendance réseau… plus de réseau, plus d’API

- le réutilisateur devient dépendant de la disponibilité de l’API (SLA), de sa stabilité dans le temps (changement dans ses specs = redéveloppement nécessaire)
- les indisponibilités des API dont on dépend s’additionnent (elles ont le mauvais goût de ne pas être HS en même temps… et attention au phénomène de cascade avec des API qui dépendent d’autres API)
- le diffuseur doit garantir de la SLA (donc coût associé) et une stabilité par du versionning (maintenir une ancienne version de l’API assez longtemps pour permettre aux réutilisateurs de s’adapter = double maintenance)
- le diffuseur doit s’occuper des montées en charge (coûts)… ou mettre des quotas (réutilisateurs impactés)
- le coût de diffusion est nettement supérieur que de déposer des données sur un bête serveur web/ftp (sauf sur les données de très grand volume et encore les coûts deviennent vite marginaux).
- certains usages des données ne sont pas envisageables via API, une API n’est souvent pas neutre car elle prévoit des modes d’accès aux données, mais ne peut pas tous les prévoir. C’est en général peu compatible avec un usage de type datascience / IA.
Comme toute techno, il ne faut pas en mettre partout par techno-idéologie, mais réfléchir là où c’est pertinent. Il faut aussi distinguer les API internes et externes, pour les internes on peut mieux gérer les inconvénients que j’ai cité que pour les externes.
Bonjour,
Je vais forcément avoir un avis biaisé (nous avons une plateforme qui permet d’ouvrir des données sous forme d’API), mais je me joins à la discussion.
Je trouve que l’ouverture des données uniquement via des fichiers rend l’information difficilement accessible au citoyen. Elle peut même induire des contraintes d’accès : les personnes lamda ne peuvent pas consulter des données comme la base Sirene dans son format fichier par exemple. L’ouverture des données par API impose aussi un effort de structuration, qui rend les données plus réutilisables, on peut être tenté d’éviter de passer par cette étape si on a juste à poser un fichier.
Mais d’un autre coté mettre uniquement une API a aussi ses problèmes, comme vous l’évoquez. Et des fois ça ne répond pas non plus à certains cas d’usage. Voir la encore le grand débat où les datascientists ont besoin des jeux de données en entier pour faire tourner leurs algorithmes.
Si possible on devrait avoir les 2 :
- Une API qui permet de rendre la données plus facilement accessible, sous réserve bien sur qu’il y ait des services construits la dessus (vue en table, en carte, moteur de recherche, data visualisation …)
- Une mise à disposition des données source ou d’un export dans un format commun.
L’open data ouvre plein d’usages, L’API est plus adaptée pour certains, les données en fichier pour d’autres. SI on fait les deux on augmente la possibilité de réutilisation qui est je pense une composante importante de l’open data.
Tout à fait d’accord avec @nicolas-bonnel. En 2019 on ne devrait pas avoir à choisir… en tout cas dans la grande majorité des cas. Les plateformes à l’état de l’art (qu’elles soient en SaaS ou déployées on premises) proposent d’ailleurs généralement les deux.
Nicolas me semble proposer un argument puissant quand il dit que l’APIfication force à avoir un modèle de données. C’est un facteur important de qualité des données, je pense. Le simple dump d’un fichier a pour conséquence qu’on peut avoir des données totalement inexploitables…
Mon avis d’“opendata lover” à 2 cts en mode citoyen et souvent via et pour OSM.
Si je n’ai pas accès à des données en mode fichier, je ne peux plus rien faire car je ne sais pas traiter des API. Je me considère déjà un peu au dessus du lot du citoyen lambda (c’est pour ca que je suis sur ce forum d’ailleurs lol) car non-techo, non-informaticien, non-géomaticen, mais pour moi le système fichier reste essentiel pour permettre au citoyen de s’approprier de la donnée et faire ses petites affaires dans son coin. Un système tout-API ferait, selon moi, que l’opendata ne serait plus si open que ca.
Je peux développer dans un autre post si la vision d’un citoyen lambda vous intéresse mais il est tard
Je ne vois pas en quoi proposer des données via API force à avoir un modèle de données.
APIfier des données tabulaires c’est très simple et sans modèle de données… et on le voit souvent.
Comme le dit Donat, pour le citoyen, l’API c’est encore moins utilisable (par lui) qu’un CSV qu’il arrivera à ouvrir avec un outil bureautique.
Par contre, pour le développeur, une API lui permet de créer une petite appli (web, mobile) facilement utilisable par le citoyen lambda… si les endpoints font ce dont il a besoin et ça il ne le contrôle pas.
Faire les deux ? Très bien si on a le temps, les moyens, les compétences… ce qui est souvent rare
Donc quand il faut choisir (et c’est souvent le cas), les fichiers téléchargeables sont quand même plus faciles et moins coûteux à publier.
Parfaitement d’accord avec @cquest, les API sont une facilité d’usage pour les développeurs mais réduisent considérablement le public atteignable directement sans intermédiaire par les données. Évidemment si l’on peut avoir les deux tant mieux, mais l’OpenData c’est avant tout des dumps complets téléchargeables à une adresse fixe selon tous les standards internationaux (10 principes Sebastopol/Sunlight, OpenDefinition OKFN, etc.).
De plus, le travail à fournir par le producteur pour fournir une API est bien plus considérable.
S’il faut choisir le fichier complet téléchargeable devrait toujours être la priorité, le développement d’une API ne saurait être qu’un bonus, pas un remplacement !
Concernant un cas concret des différentes modalités d’accès aux données ouvertes, le répertoire national des aides aux entreprises fournit des fichiers téléchargeables (csv, json ou xml au choix) ET une API Rest avec authentification.
Pour le suivi des mises à jour, 2 services complémentaires sont mis à disposition :
- Un webhook avec la méthode POST
- Une synchronisation cloud … avec Google Drive
Que pensez-vous de ces modalités complémentaires pour le suivi des mises à jour ?
C’est très bien de proposer aussi ces cerises sur le gâteau… mais l’essentiel c’est le gâteau
Grosso modo d’accord avec tout ce qui a été dit. Avec une remarque cependant :
L’API, c’est l’open data du point de vue du développeur d’application / de site web. C’est la possibilité de construire un développement en manipulant des briques, sans avoir à se poser la question de quelle donnée je prends : y a juste des paramètres à rentrer.
C’est pour moi la principale raison de son succès : fort peu de personnes veulent manipuler des données brutes. Les deux sont cependant complémentaires et nécessaires. Un ex : une API sur les retards SNCF sans des données chronologiques serait s’empêcher de dire, ca s’améliore ou ca emprire.
Amis de l’OpenData, amateurs ou pas d’API, je vous soumet ce brouillon d’article afin d’avoir vos retours avant publication…
Les questions d’outillage et de gestion du cycle de vie de la donnée, au sens large, sont aussi au coeur de ce petit débat entre libristes sur linuxfr.org : https://linuxfr.org/users/naga-2/journaux/donnees-libres-analyse-critique-de-l-open-data .
Pour information, on vient de lancer un portail API public. Ce portail API (https://portail-api.montpellier3m.fr/) ne concerne donc pas toutes les données de la collectivité mais uniquement celles pour lesquelles la plus-value d’un accès API est réelle.
Il s’agit, pour la phase bêta de ce portail, des disponibilités en temps réel des vélos en libre-service (VéloMagg), des données de comptage des vélos issues des Ecocompteurs, de la disponibilité en temps réel des places dans les parkings en ouvrages du territoire.
Pour ce faire nous avons opté pour la plateforme open source Fiware (context broker) qui nous permet de récupérer les trames des différentes sources et de les stocker selon des modèles de données standardisés (NGSIv2 et NGSI-LD). Enfin pour accéder à ces données nous avons lié la plateforme Fiware à une interface API (Kong) qui offre les fonctionnalités classiques.
Le schéma d’architecture mise en place en collaboration avec nos deux partenaires industriels Atos (Fiware + Kong) et Synox (Iot).
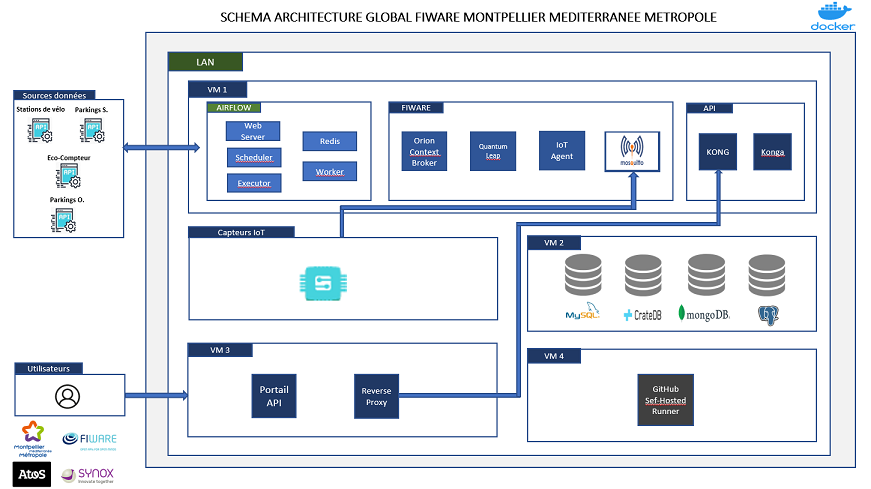
Bonjour Jérémie @OpenData_Montpellier et merci pour le partage de cette initiative. Je m’interroge sur les composants du schéma d’architecture dans le bloc Fiware : Orion context broker implémente les spécifications de NGSIv2 mais pas celles de NGSI-LD (Orion LD) ? Pourquoi le MQTT Broker Mosquitto apparaît-il dans le bloc Fiware ?
Salut, voici quelques éléments de réponse,
Effectivement le Context Broker Orion utilisé dans l’architecture Fiware de la Métropole ne gère que les interfaces NGSI-v2 car la standardisation et la contextualisation des données de la Métropole sont effectués selon les spécifications V2. Ainsi les données extraites du portail API ne sont pas au format Linked-Data (LD).
Un courtier de message (MQTT Broker) est utilisé au sein de cette architecture afin de permettre un couple lâche et non directe telle qu’avec des communications directes en http (consommatrice en énergie). Le broker Mosquitto est interfacé avec l’IoT Agent pour mettre en queue les messages envoyés par les capteurs IoT telles que les places PMR. L’IoT Agent va alors s’abonner à ses messages et les traiter au fil d’eau en contextualisant et standardisant l’information avant de la pousser vers le Context Broker Fiware (Orion).
API ou pas API. Pour moi ce sera API.
API ne veut pas dire exclusion des autres formats.
API ne veut pas dire exclusion de certains publics puisque les autres formats sont disponibles
API car cela offre des fonctionnalités utiles et c’est un levier pour ouvrir les données
Pour la petite histoire le jeu de données « Liste des services de santé au travail (SST) » est disponible car un utilisateur externe représentant une société d’intérim importante souhaitait une API plus pratique pour lui que le pdf existant.
Voilà ma petite vision à date ![]()