Voici comme convenu une synthèse sur ce sujet de discussion lié à l’évolution du format CSV.
Celle-ci est construite à partir de vos nombreuses contributions (cf historique) et d’un sondage Mastodon.
Le sondage a obtenu 53 réponses à la question « quelle solution est à mettre en oeuvre ? » avec la répartition suivante parmi les quatre réponses possibles :
- conserver le format CSV (53%)
- utiliser le format JSON (32%)
- utiliser un format binaire (ex. Parquet) (6%)
- utiliser un autre format texte (ex. XML, YAML) (9%)
La synthèse s’appuie sur les questions posées dans le message initial.
J’espère que celle-ci reflète bien tous les avis exprimés.
Bonne lecture !
1 - Le format CSV est-il obsolète ?
La première réponse est oui. En effet, la norme (RFC4180) est très restrictive et n’a pas été mise à jour depuis 2005 :
- elle ne connait que les caractères ASCII (pas les Unicode notamme UTF8)
- elle n’identifie qu’un séparateur : la virgule (pas le « point-vigule »)
- elle n’autorise les caractères « virgule », « fin de ligne », « saut de ligne » et « guillemet double » que dans les champs « quotés » (encadrés par deux guillemets doubles). Seul le « guillemet double » peut être échappé (par un autre « guillemet double »).
Le RGI (Référentiel Général d’Interopérabilité), dans sa dernière version de 2015 (qui demanderait à être actualisée), avait déja classé ce format « en fin de vie ».
La deuxième réponse est non. En effet, le format CSV, malgré ses limitations, est le format le plus utilisé dans les échanges de données tabulaires.
Il est simple et compréhensible, lisible par n’importe quel éditeur de texte et la majorité des applications traitant des données tabulaires proposent ce format d’échange.
Cependant, les formats CSV utilisés sont des variantes et extensions de la norme permettant par exemple d’avoir d’autres types de séparateur, d’intégrer des formats UTF8 ou encore d’avoir une gestion d’entête plus ou moins sophistiquée. L’utilisation de ce format associé à une compression (ex. zip) permet d’obtenir des tailles de fichiers comparables à d’autres solutions plus optimisées.
En synthèse :
- le standard est effectivement obsolète,
- la pratique sur ce format (qui n’est plus standard) reste forte
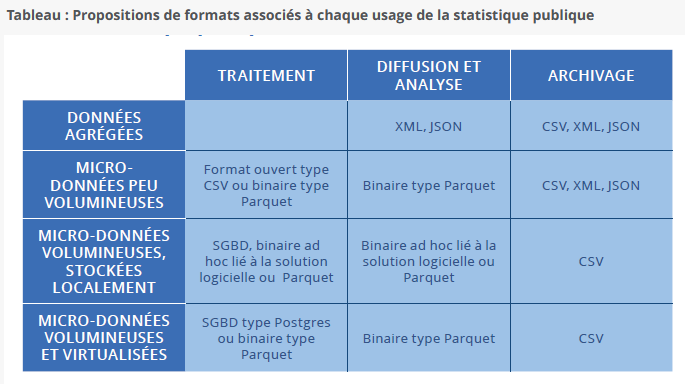
2 - Faut-il engager une réflexion sur un format alternatif ?
La encore, les avis sont partagés :
- les tenants du non précisent que malgré une absence de standard applicable, on arrive à fonctionner avec les limitations identifiées et qu’à ce jour il n’y a pas de solution alternative suffisamment accessible à tous et notamment au travers des tableurs qui représentent la majorité des usages de données tabulaires. La réponse au sondage allait également dans ce sens.
- les tenants du oui mettent en avant les limitations du format qui conduisent à des problèmes de non qualité de plus en plus inacceptables (données non protégées, pas de gestion du typage, les langues, les caractères spéciaux, mauvaises performances de lecture/écriture sur des jeux de données importants …).
En synthèse, la réponse est dans la question : Comme il n’y a pas de format alternatif largement déployé, on continue de fonctionner avec l’existant mais si un format
alternatif émerge et répond aux limitations et attentes identifiées, il remplacera le format CSV.
3 - Quel serait le format alternatif ?
De même que pour la question précédente, deux approches distinctes émergent :
- ceux qui privilégient les performances (données de taille importante, temps de réponse), ou l’intégration (avec les outils BI ou de stockage fichiers ou base de données) mettent en avant les formats binaires intégrant des fonctions évoluées (ex gestion du typage de données, algorithmes de compression, segmentation des données) comme par exemple le format Parquet (objet d’une promotion forte actuellement).
- ceux qui privilégient la capacité à traiter des données complexes (cf. sujet spécifique), la simplicité et la pérennité sont plutôt partisans d’une solution à base de format texte. Le candidat le plus naturel est le format JSON (cf résultats du sondage mastodon). Cependant, ce format est plus un langage de description de données; il nécessite donc une déclinaison spécifique dédiée aux formats tabulaires qui reste à construire.
Les deux approches sont complémentaires (avoir de bonnes performances sur des volumes de données importants n’est pas toujours compatible avec la capacité à traiter des données complexes avec un niveau sémantique élevé). Les deux solutions sont donc nécessaires. Il reste néanmoins dans la seconde approche à identifier une solution JSON déployable sur la majorité des applications (ce qui prendra du temps).
4 - Est-ce que le format de récupération des données doit être identique entre une récupération via API ou une récupération via fichier ? Est-ce que la solution proposée dans la note jointe vous semble intéressante ?
Peu de réponses ont été apportées à ces questions qui sont trop orientées sur une solution technique. Celles-ci ne pourront être abordées que dans le cadre d’une réflexion autour d’un format texte alternatif qui reste à engager.