Céile, écrit comme ça, ça me semble présager des usages ou réduire l’opendata uniquement à la création de services “utiles” à la consommation immédiate. En fait je ne sais pas ce qu’est “l’usage de l’opendata”.
Si je prends les données sur la qualité de l’eau potable, je peux effectivement faire une appli qui me donne les résultats des dernières mesures près de chez moi, mais avec la série longue je peux calculer la régularité de cette qualité et son évolution dans le temps (ce qu’une appli pourrait aussi fournir comme info).
Certaines données perdent une partie de leur intérêt avec le temps, c’est sûr, sauf pour faire des stats.
A quoi bon conserver dans OpenEventDatabase l’ensemble des incidents sur le réseau RATP qui sont diffusés en temps réel ?
Et bien ça qui m’a permis de voir que la RATP a par exemple changé ses règles pour les “colis abandonnés”, dont le nombre a été divisé par 20 d’un mois sur l’autre en septembre 2017 si ma mémoire est bonne.
Présageons le moins possible de ce qui peut être fait des données ouvertes. C’est même souvent ces usages auxquels on ne pense pas à l’origine qui sont les plus intéressants.
Je vous rejoint totalement sur la question de l’authenticité des données… mais là, leur mode de diffusion actuel ne garantit pas grand chose.
Rares sont les jeux de données où l’on a un hash signé pour garantir intégrité et origine.
C’est justement dans cette logique d’archivage que nous avons développé notre “Data Library” chez nam.R. Cette bibliothèque a pour objectif de contenir l’ensemble des références open data puisés des quelques centaines de portails ouverts sur le territoire.
On a fait le choix de télécharger les fichiers et stocker les fichiers plutôt que de seulement faire référence aux métadonnées. Avoir en stock les fichiers permet de produire automatiquement des informations très utiles (comme extraire le poids du fichier, son extension, son schéma…) mais aussi de garantir son accessibilité !
Et c’est un véritable enjeu de pouvoir garantir qu’on pourra disposer à moyen terme des données qui sont potentiellement utilisées par nos Data Scientists.
C’est d’ailleurs la raison pour laquelle nous n’écrasons les fichiers étant mis à jour, et préférons millésimer les versions étant donné que ce travail ne sera pas forcément fait par le fournisseur.
Enfin, ces millésimes permettent, comme le dit @cquest d’établir des tendances qui peuvent être extrêmement intéressantes. Par exemple, l’annuaire de l’éducation qui est tenu à jour par le Ministère sur leur portail OpenDataSoft n’existe qu’en version live et ne permet pas d’identifier les créations et fermetures d’établissements.
Bonjour à tous et merci pour cet intéressant débat.
Sur l’aspect “sauvetage” de données mis en ligne (open data ou pas d’ailleurs) par la puissance publique par peur d’effacement pour raison technique ou politique, la démarche ne peut qu’honorer les citoyens qui s’y investissent.
Pour ce qui est de l’archivage en tant qu’archiviste j’ai le sentiment de revenir au début de ma carrière il y a 10 ans où nous devions apprendre à travailler avec les informaticiens pour la partie numérique de la production. Ce que je lis ici n’est pas un archivage mais une sauvegarde, et une mise à disposition en ligne. Qu’on ne se trompe pas j’estime que ceci est déjà beaucoup surtout quand on parle d’initiative privée. Mais ce n’est pas la même chose que l’archivage.
On peut voir que dans la plupart des messages que le sujet est traité de façon technique : quels outils, quels formats, quelles technologies etc… Ceci occulte donc le plus important dans un archivage : le travail humain et organisationnel.
En ce sens, je pense qu’il faut aller regarder du côté des États-Unis où suite à l’élection de D.Trump des groupes de citoyens ont archivé un maximum de données notamment liées à l’environnement avant que l’administration ne les supprime. Dans ces groupes étaient présents des bibliothécaires et des archivistes apportant leurs compétences en termes de gestion documentaire.
Sujet qui n’est pas soulevé ici et qui pourtant est au cœur de l’archivage : Que va-t-on éliminer / supprimer ? Un important débat a eu lieu en France sur la notion d’archives essentielles et il a fallu beaucoup de pédagogie pour expliquer au grand public que nous ne conservions pas tout mais en respectant de nombreuses règles (lois, circulaires,décrets, corpus professionnel). Donc navré de décevoir mais tout ne sera pas conservé par des services d’archives (publiques ou non) car ce n’est ni possible et qu’il est même sain de savoir éliminer.
Pour finir, je dirai qu’il y a un fort intérêt à ce que la puissance publique s’empare du sujet car quelque soit l’investissement de particulier il n’apporte aucune garantie dans le temps. Ce que permet un service d’archives c’est d’envisager la conservation sur le temps long et ceci en siècles.
Edit : une ressource sur une initiative citoyenne et archives aux USA Reclaim the records qui peut inspirer et nourrir la réflexion
bravo pour ce projet concret
Oui clairement c’est utile, ça fait penser au software heritage en effet.
Je crois aussi qu’il faudrait (moissonner et) archiver des documents et pas que l’open data, les délibérations, ou les dossiers de marchés publics.
Les “wget -r” s’enchaînent et les disques se remplissent petit à petit… et nettement plus vite avec la fibre
Je vais bientôt auto-héberger “data.cquest.org”, actuellement hébergé sur une dédibox, car le disque (1To de SSD) est quasi plein, et cela fera un serveur en moins à louer.
Budget à rebasculer sur la deuxième fibre et ma facture Enercoop
Histoire de prioriser l’archivage, quelles sont, selon vous, les jeux de données par lesquels commencer ?
Par exemple, les données de référence du Service Public de la Donnée, en partie déjà fait, à compléter, surtout sur la partie archive.
J’ai une copie en cours des données de la DILA… ce qui fait déjà un beau morceau et le débit est plutôt bon (dans les 60 à 100Mbps, visiblement pas volontairement limité).
Autre archivage en cours… les photos aériennes anciennes de l’IGN. Cela les rendra plus facilement accessibles, car aujourd’hui même si l’accès est libre, il n’est pas aisé (clicodrome).
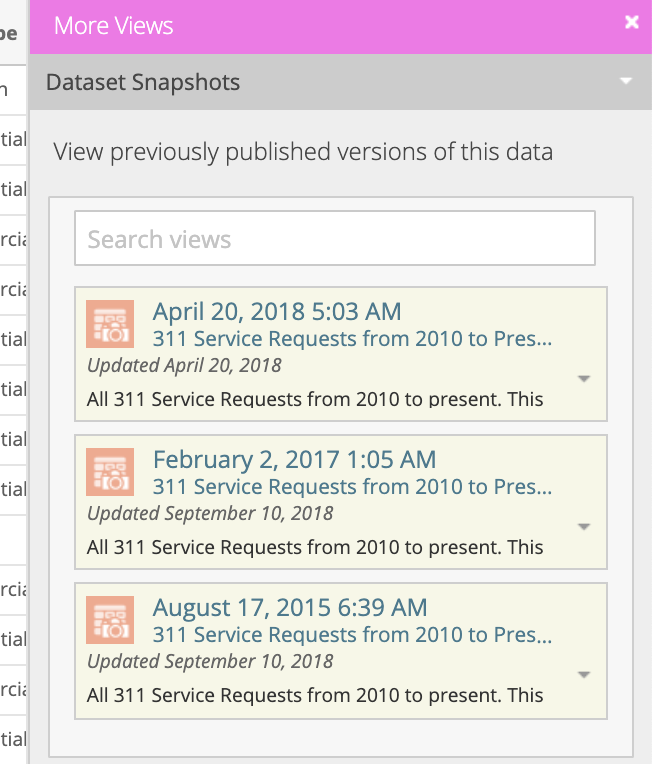
Je ne connaissais pas cette fonctionnalité de Socrata, merci pour le partage. Néanmoins, ces « snapshots » restent une option qui doit être activée au cas par cas par le producteur, je suppose au moment de la publication, et pouvant être aussi supprimée à posteriori. Le cliquodrome limite aussi l’exploitation de ces « versions »… C’est mieux que rien, mais on est encore loin du versionnement systématique et aussi ouvert que les données elles-mêmes. Il me paraît en effet crucial de pouvoir accéder aux données brutes, et ce pour chaque étape où elles ont été modifiées, y compris avant que le portail n’ait transformé les données à l’import.
Techniquement, ce n’est pas anodin à implémenter et il me paraît compliqué et peu souhaitable de le faire pour les portails actuels, qui sont globalement assez monolithiques.
J’ai bon espoir que d’autres options puissent émerger, avec frontend et backend qui seraient découplés, où l’on pourrait plus facilement exploiter et valoriser les données dans un environnement, une interface et avec des technos adaptées, sans qu’elles restent enfermées là où elles ont été publiées avec des contraintes propres au portail.
J’ai profité du calme de l’été pour crâmer un peu de bande passante et d’espace disque.
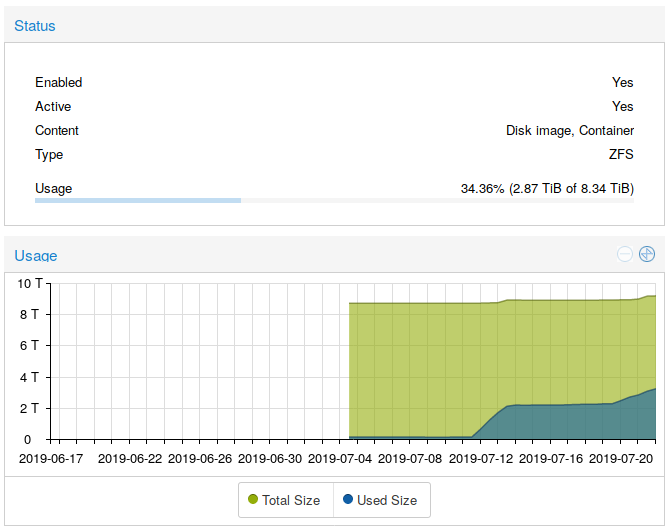
L’archive des données publiées sur data.gouv.fr est fait, ainsi que la DILA (536Go) qui arrive second derrière le Géoportail de l’Urbanisme (538Go de ZIP avec beaucoup de PDF et une pincée de shapefile).
Total actuel: 5To (dédupliqué et compressé par ZFS)
Hier, j’ai démarré l’archivage des portails OpenDataSoft…
Les scripts d’archivage sont prévus pour fonctionner en mise à jour quotidienne.
Pour les portails OpenDataSoft, j’ai ajouté l’archivage de la version « géographique » des données, en récupérant aussi le fichier au format geojson lorsque c’est approprié. Il est quand même bien plus facilement exploitable que les CSV contenant des bouts de geojson
Autre ajout… l’exclusion des jeux de données qui ne sont que des extraits de référentiels nationaux:
base sirene (rarement à jour en plus)
répertoire national des élus
prévision de météo france
registre parcellaire graphique
etc…
Premier décompte:
14000 jeux de données
mais 8000 différents, il y a beaucoup de jeux qui semblent identiques disponibles sur plusieurs portails, mais il n’est pas facile de s’y retrouver pour ne garder que l’original
Next steps:
l’archivage des « pièces jointes », certains jeux de données comme les GTFS sont souvent publiés de cette façon.
pour les jeux de données qui en fait ne font que lister des URL de téléchargement de fichiers, archiver aussi ces fichiers. Certains GTFS sont publiés comme ça, mais aussi les dalles d’ortho-photographies ou des documents numérisés et le contenu utile du jeu de données se trouve au bout de ces liens… environ 500 jeux de données sont concernés.
Superbe boulot, qui pourrait peut être aussi trouver des usages pour ceux chez Opendata France ou chez nous qui aiment bien analyser ce qu’il y a sur les portails… Là ça fait un point d’accès unique avec une arborescence normalisée… Poke @samgoeta@mathieu etc.
Bravo Christian ! Tu as raison de laisser pour l’instant de côté les questions liées au versioning/diff et de t’être lancé sans bikeshedder outre mesure.
Je découvre aujourd’hui une autre initiative du même genre : The Government Data Graveyard, qui n’archive cependant pas les jeux de données mais recense, plutôt symboliquement, ceux dont la publication a été interrompue.
L’auteure, Anna Powell-Smith, a également un blog sur le sujet : Missing Numbers.
Je suis comme ça… quand j’ai une idée, il faut que j’essaye de la valider en commençant la réalisation.
Ça permet d’avancer et ensuite de rectifier le tir uniquement là où c’est nécessaire.
Je pense déjà devoir rectifier le tir sur l’organisation des archives, car le premier jet est trop calqué sur l’organisation des portails OpenDataSoft vu que j’ai commencé par ça.
En codant l’archiveur pour Koumoul et celui pour CKAN, je vois qu’il y peut y avoir plusieurs fichiers de données pour un jeu de données (CKAN).
C’est aussi le cas pour uData (data.gouv.fr), j’aurais dû y penser !
Il faut donc adapter l’organisation de l’archive pour ça.
Les timestamps ISO complets sont bien longs et « bruitent » un peu trop les noms des fichiers, je passe donc en mode compact: AAAAMMJJTHHMMSSZ
Pour les fichiers externes listés par le contenu d’un jeu de données, j’ai (temporairement ?) coupé leur récupération si il y en a plus de 1000.
Ce qui est dommage c’est que la gestion par les producteurs des metadonnées est quand même très approximative sur la partie date de modification des données et metadonnées. Beaucoup de metadonnées voient leur date de modification changer quotidiennement alors que leur contenu ne change pas.
Cela oblige à les récupérer, les comparer aux précédentes et désormais je ne versionne que si il y a eu un changement effectif. Cela doit venir d’alimentation automatique des portails qui se font en batch même si rien n’a été modifié (y compris dans les données).
Pour les données, c’est bien sûr encore plus problématique.
Autre point… les données « temps-réel ». Quelle historisation faire et donc à quelle fréquence ?
J’envisage de sortir des stats et un dashboard pour avoir une vue d’ensemble.